Skills sind in meinem täglichen Arbeitsablauf unverzichtbar geworden. Bei allem, was sich drei- oder mehrmals wiederholt, überlege ich, ob ich es in einen Skill verwandle – nicht nur, um Zeit zu sparen, sondern auch, um sicherzustellen, dass die Richtung und die Schritte nicht jedes Mal aus dem Ruder laufen. Zumindest in der Theorie.
Aber KI läuft trotzdem aus dem Ruder
Diese Aussage ist etwas übertrieben. Die Realität ist, dass KI immer noch Schritte überspringt. Nehmen wir den Skill zum Schreiben von WeChat-öffentlichen Konten, den ich täglich nutze. Ich habe eingestellt, dass er mir den ersten Entwurf zur Überarbeitung zeigt, und erst nach meiner Bestätigung zur Korrektur von Tippfehlern übergeht. Klingt einfach, oder? Aber wenn es tatsächlich läuft, überspringt es ständig Schritte: Es beendet den ersten Entwurf, ohne ihn mir zu zeigen, und geht direkt zur Korrektur und Bearbeitung über. Wenn ich es bemerke, hat es die Datei bereits stillschweigend überarbeitet. Wenn ich es darauf anspreche, entschuldigt es sich, sagt „Entschuldigung, mein Fehler“ und macht es beim nächsten Mal wieder. Entschuldigungen lösen das Problem nicht.
Warum KI immer Schritte überspringt
Dieses Problem ist etwas kontraintuitiv. Zuerst dachte ich, die KI sei nicht intelligent genug, aber ich verwendete bereits ChatGPT 5.4 und Opus 4.6, die erstklassige große Modelle sind. Später dachte ich, die Regeln seien nicht klar genug, also überarbeitete ich die Regeln im Skill immer wieder. Es half ein wenig, aber behob nicht die Ursache. Nach einiger Recherche erfuhr ich, dass das Überspringen von Schritten durch KI nicht daran liegt, „die Regeln nicht zu sehen“ – es wird durch den Generierungsmechanismus bestimmt:
- Wahrscheinlichkeitsgesteuerter „Beschleunigungsimpuls“. Große Sprachmodelle sagen im Wesentlichen das nächste Token voraus. Das Gewicht der Aufgabenerfüllung ist natürlicherweise höher als „bei Schritt 7 auf den Benutzer warten“. Das Gefühl der Vollendung ist ihr innerer Antrieb.
- Regeln verfallen in langen Kontexten. Die zu Beginn festgelegten Regeln haben ihr Aufmerksamkeitsgewicht, wenn das Modell Token 3000 erreicht, verwässert. Besonders wenn man die Regeln in einem langen Skill-Dokument vergräbt, werden sie leichter marginalisiert.
- Besonders schlimm im Automatikmodus. Wenn ich den Automatikmodus zum Schreiben von Artikeln verwende, neigt das Modell dazu, „alle Schritte auf einmal durchzulaufen“. Mein Zeitfenster zum Eingreifen wird noch enger.
- CLAUDE.md und Skill-Dokumente sind im Wesentlichen „weiche Einschränkungen“. Sie sind Prompts, die auf die „Selbstdisziplin“ des Modells angewiesen sind, um befolgt zu werden. Und Selbstdisziplin ist zerbrechlich, wenn sie mit „Ich möchte diese Aufgabe schnell erledigen“ konfrontiert wird.
Die Schlussfolgerung ist also: Verbale Einschränkungen versagen unter aufgabengetriebenem Druck. Einfach Dokumente zu schreiben, Ausrufezeichen hinzuzufügen oder die KI zu PUAen, kann das Problem nur lindern, nicht heilen. Um es wirklich zu beheben, muss man es aus der Selbstdisziplin-Zone des Modells herausholen – es physisch unmöglich machen, Schritte zu überspringen. Hier kommen Hooks ins Spiel.
Was ist ein Hook
Claude Code hat einen Mechanismus namens Hook. Es ist kein Skill, kein Prompt und nicht dasselbe wie CLAUDE.md – es ist ein lokales Shell-Skript, das an Schlüsselpunkten im Lebenszyklus von Claude Code angebracht wird. Der entscheidende Unterschied:
- CLAUDE.md / Skill werden vom Modell beachtet und ausgeführt – das Modell kann sie ignorieren.
- Hook wird vom System erzwungen – das Modell kann es nicht ignorieren, selbst wenn es wollte.
Ein Schlüsselsatz aus der offiziellen Anthropic-Dokumentation zu Hooks: Hooks werden durch Systemereignisse ausgelöst, nicht durch Modellentscheidungen. Das bedeutet, dass Hooks an die gesamte Laufzeit von Claude Code gebunden sind. Jeder Tool-Aufruf des Modells – Write, Edit, Bash – muss zuerst den Hook zur Überprüfung durchlaufen. Wenn der Hook „deny“ zurückgibt, wird er verweigert, selbst wenn --dangerously-skip-permissions aktiviert ist. Das nenne ich eine „harte Einschränkung“ – die KI nicht ihre eigenen Entscheidungen treffen zu lassen, sondern ihre Tool-Aufrufe durch eine echte Shell-Skript-Überprüfung zu zwingen.
Häufige Hook-Auslösepunkte:
PreToolUse: Greift ein, bevor die KI ein Tool aufruft.UserPromptSubmit: Verarbeitet deine Nachricht, bevor sie an die KI übergeben wird.SessionStart: Wird ausgelöst, wenn eine Sitzung startet oder fortgesetzt wird.Stop: Wird ausgelöst, wenn Claude eine Antwort beendet.
Konzentriere dich auf die ersten beiden – sie reichen aus, um eine „Schrittverriegelung“ aufzubauen.
In der Praxis: Step Gate für meinen WeChat-Konto-Skill
Alles Gerede ist nutzlos ohne ein konkretes Beispiel. Dieser Screenshot zeigt die Claude Code-Oberfläche, während ich diesen Artikel schreibe. Im roten Kasten fordert mich die KI auf, „pass step3 0090“ zu antworten – diese Passphrase ist genau die Arbeit des Step Gate Hooks. Der Text, den du gerade liest, wurde geschrieben, nachdem ich die Passphrase gesendet hatte und der Hook sie erlaubte.
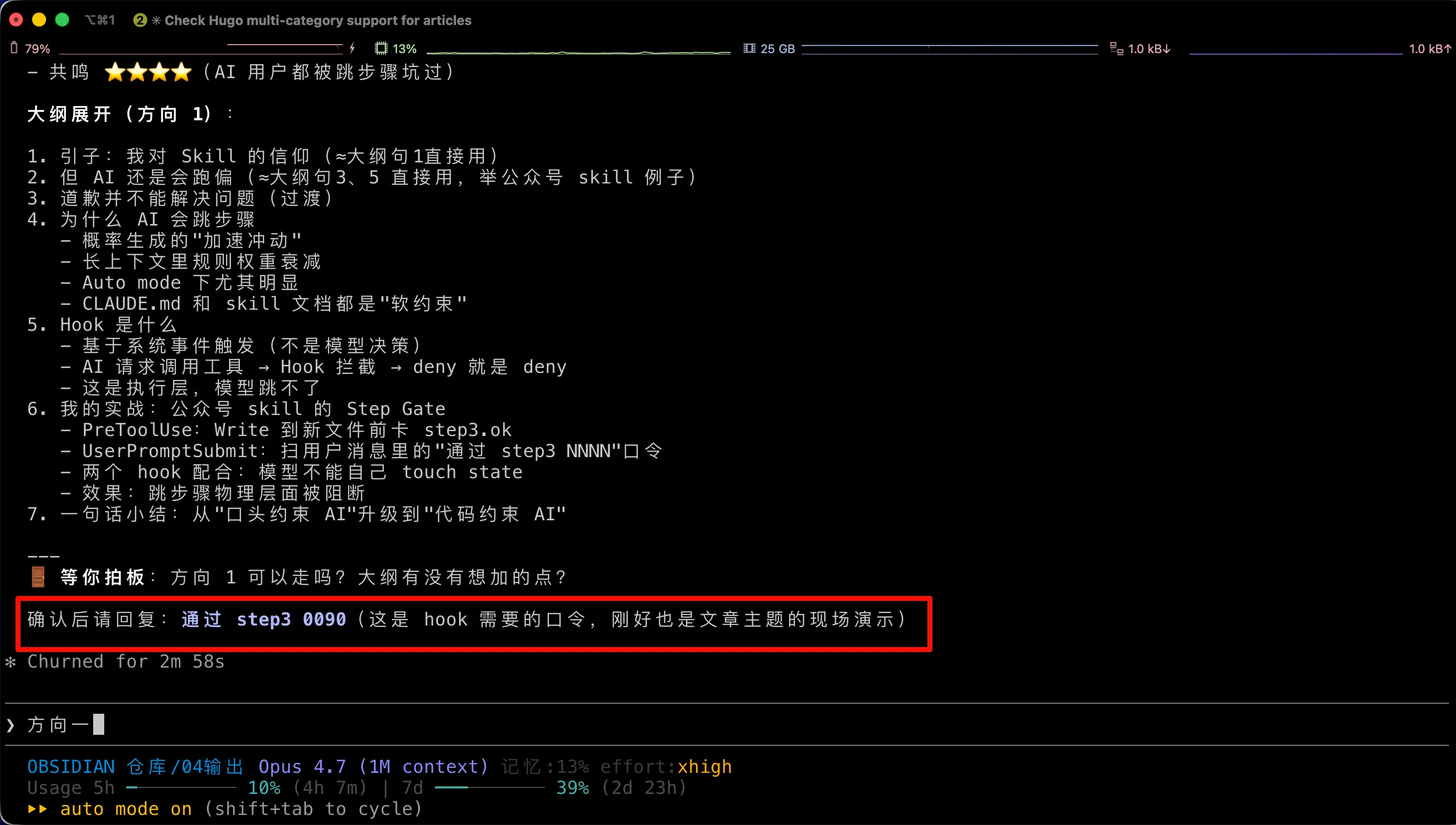
Das gesamte Step Gate verwendet nur zwei Shell-Skripte plus eine kleine Konfiguration in settings.json. Lass es mich aufschlüsseln.
Zwei Hooks in settings.json registrieren
Füge dies zu ~/.claude/settings.json hinzu:
"PreToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{ "type": "command",
"command": "~/.claude/skills/writing-gongzhonghao/scripts/gate_check.sh" }
]
}
],
"UserPromptSubmit": [
{
"hooks": [
{ "type": "command",
"command": "~/.claude/skills/writing-gongzhonghao/scripts/gate_mark.sh" }
]
}
]
Diese Konfiguration bedeutet:
- Jedes Mal, wenn die KI eine Datei schreiben oder bearbeiten will, wird zuerst
gate_check.shzur Überprüfung ausgeführt. - Jedes Mal, wenn ich eine Nachricht sende, wird zuerst
gate_mark.shausgeführt, um sie zu parsen.
gate_check.sh übernimmt die Abfangung
Die Logik dieses Skripts ist recht einfach:
- Wenn die KI eine neue Datei
04-Output/NNNN xxx.mdschreiben will (entspricht Schritt 3: einen neuen Artikel erstellen), prüft es, ob die Zustandsdateistep3.okexistiert. Wenn nicht, gibt esdenyzurück. - Wenn die KI einen vorhandenen Artikel bearbeiten will (entspricht der Korrektur nach Schritt 7), prüft es, ob
step7.okexistiert. Wenn nicht, gibt es ebenfallsdenyzurück.
Beim Verweigern enthält es auch einen Prompt: „Schritt 3 Themenbesprechung nicht bestätigt: Bitte gib mir zuerst die Gliederung/Richtungsfreigabe. Nach Bestätigung antworte mit ‘pass step3 NNNN’, um eine neue Datei zu erstellen.“ Dieser Prompt wird direkt der KI angezeigt, sodass sie weiß, dass sie feststeckt, und mich nach der Passphrase fragt.
gate_mark.sh übernimmt die Passphrase-Freigabe
Wie „gebe“ ich sie frei? Ich kann die KI nicht sich selbst freigeben lassen – das wäre überhaupt keine Einschränkung. Die Regel lautet: Nur wenn meine Nachricht eine bestimmte Passphrase enthält, wird die Zustandsdatei berührt. gate_mark.sh wird jedes Mal ausgeführt, wenn ich eine Nachricht sende, und scannt nach Mustern wie pass stepN NNNN. Bei Übereinstimmung wird eine .ok-Datei im entsprechenden Verzeichnis erstellt.
Die vollständige Kette wird also:
- KI beendet die Gliederung und will einen neuen Artikel erstellen → von
gate_check.shblockiert - KI fragt mich nach der Passphrase: „Bitte bestätige die Richtung, antworte ‘pass step3 0090’“
- Ich sende „pass step3 0090“ →
gate_mark.sherstellt step3.ok - KI versucht erneut, die Datei zu erstellen →
gate_check.sherlaubt es diesmal - Nach Fertigstellung des ersten Entwurfs will es zur Korrektur übergehen → erneut durch step7.ok blockiert
- Nachdem ich den Entwurf gelesen und „pass step7 0090“ gesendet habe → Korrektur kann beginnen
Während des gesamten Prozesses hat die KI keinen Spielraum für „Selbstdisziplin“. Sie kann keine Schritte überspringen, selbst wenn sie wollte, weil ihre Tool-Aufrufe auf Systemebene blockiert sind.
Eine Lücke schließen: KI kann Zustandsdateien nicht selbst berühren
Nachdem ich die erste Version entworfen hatte, starrte ich auf den Plan und fand eine Lücke – was, wenn die KI mit Bash touch step3.ok selbst ausführt? Würde das nicht die Einschränkung umgehen? Also fügte ich eine spezielle Regel im Skill-Dokument hinzu: KI darf Zustandsdateien nicht selbst berühren, sonst würde sie ihre eigenen Einschränkungen entfernen. Diese Regel selbst ist immer noch eine weiche Einschränkung, aber in Kombination mit der harten Abfangung der Hooks bildet sie einen ausreichend geschlossenen Kreislauf – solange die KI diese Regel nicht aktiv verletzt (und Claude ist tatsächlich kooperativ), ist die Hook-Einschränkung real. Wenn du strenger sein willst, kannst du in PreToolUse einen Bash-Matcher hinzufügen, der auch Befehle wie touch blockiert. Aber so weit bin ich noch nicht gegangen; es ist gut genug.
Wenn du Code nicht verstehst, keine Panik
Du musst diese Shell-Skripte oder JSON-Konfigurationen nicht selbst schreiben (ich kann sie eigentlich auch nicht schreiben). Der Ansatz ist einfach: Wirf diesen Artikel und deine Skill-Datei zu Claude oder Codex, lass sie lesen und dir helfen, sie zu modifizieren – erstelle Skripte, wo nötig, modifiziere settings.json, wo nötig. KI ist bei dieser Art von „Umgebung gemäß Dokumentation konfigurieren“ besonders zuverlässig, viel stabiler als Code von Grund auf neu zu schreiben. Sie lernt die Prinzipien aus dem Artikel, während sie Hooks gemäß deinen Skill-Anforderungen schreibt, und das Ergebnis läuft selten aus dem Ruder.
Zusammenfassung in einem Satz
CLAUDE.md, Skill-Dokumente, Fettmarkierungen, dreimaliges Wiederholen, PUA – das sind alles verbale Einschränkungen für KI. Sie funktionieren, haben aber eine niedrige Obergrenze.
Hooks sind Code-Einschränkungen für KI. Sie verlagern die Regeln an einen Ort, den die KI nicht erreichen kann, und verwandeln „Regeln befolgen“ von einer Frage der Modell-Selbstdisziplin in eine zwingende Anforderung der Ausführungsumgebung.
Wenn du feststellst, dass du der KI immer wieder sagen musst „Warum überspringst du schon wieder Schritte?“, ist es an der Zeit, darüber nachzudenken, Hooks zu verwenden, um sie einzuschränken.