DeepSeek hat endlich das V4-Modell veröffentlicht. Ich habe es in den letzten Tagen ausprobiert und es fühlt sich großartig an, besonders das Flash-Modell mit seinem hervorragenden Preis-Leistungs-Verhältnis. Mein eigenes Ausgaben-Tracking-Miniprogramm hatte ursprünglich eine Antwortzeit von 5 Sekunden, jetzt sind es nur noch 2,5 Sekunden. Kurz gesagt: flüssig!
Der einzige Nachteil ist, dass das Pro-Modell nicht sehr günstig ist. Laut der offiziellen Website werden die Preise weiter sinken, sobald die heimische Chipversorgung in der zweiten Jahreshälfte hochgefahren wird.
Unerwarteterweise bekam das Pro-Modell zwei Tage später einen zeitlich begrenzten Rabatt von 75% (und ich vermute, dieser Rabatt könnte langfristig sein). Gestern haben sie auch den Preis für Cache-Treffer auf ein Zehntel des ursprünglichen Preises gesenkt! Was soll ich noch sagen? Zeit, aufzustehen und kräftig in die Pedale zu treten!
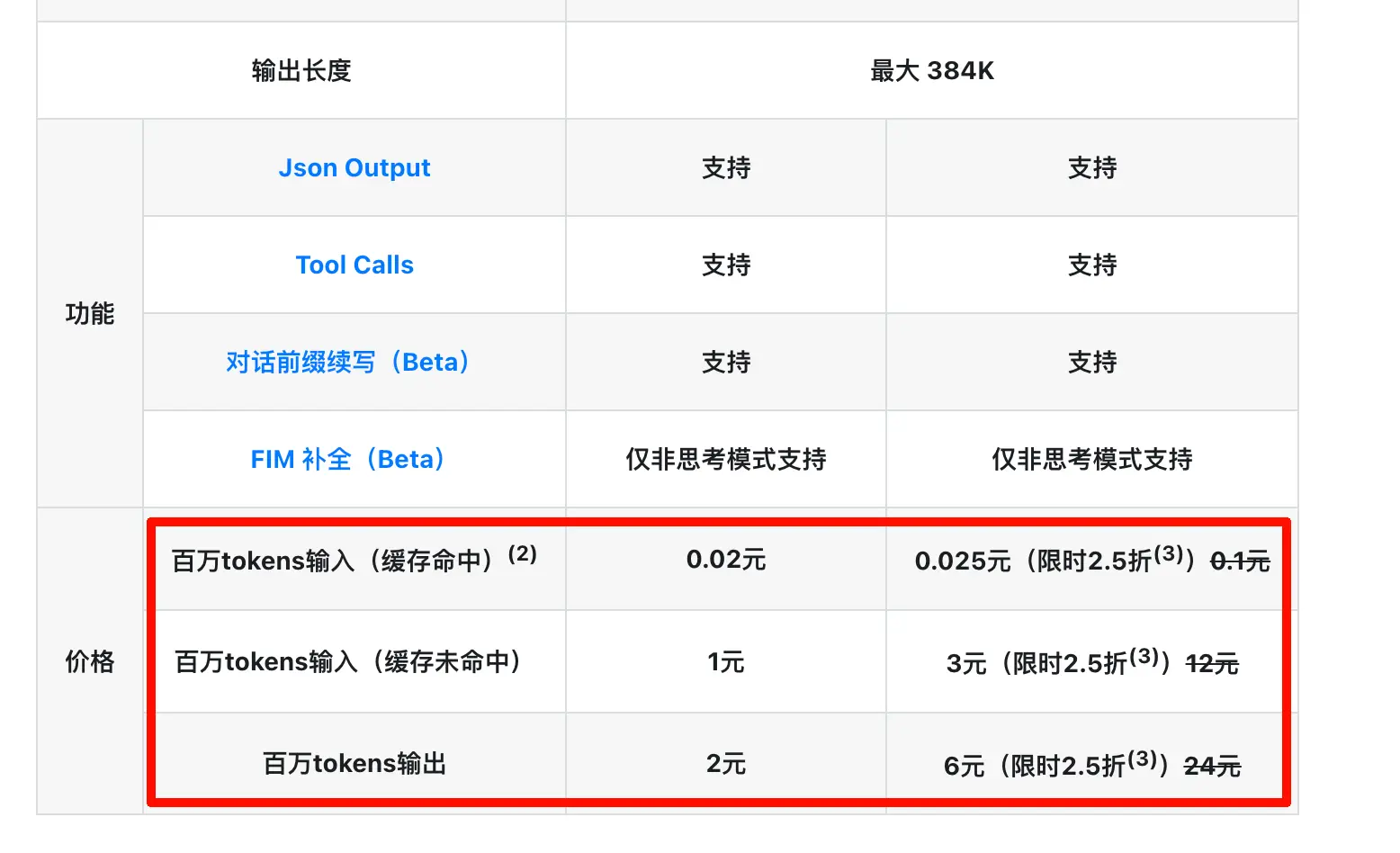
Das ist der DeepSeek, den wir kennen! Vor ein paar Tagen habe ich noch bestimmte Coding Plans dafür kritisiert, dass sie schwer zu bekommen sind und eine schlechte Erfahrung bieten. DeepSeek scheint den gesamten API-Preis direkt unter den der Coding Plans zu senken. Besonders jetzt, wo viele Coding Plans die Nutzung außerhalb der Programmierung verbieten, sticht DeepSeek’s Aufrichtigkeit noch mehr hervor.
Manche Coding Plans verbieten dir vielleicht die Nutzung, wenn du Übersetzungen integrierst, aber DeepSeek ist das egal – nutze es, wie du willst.
GPT-5.5 und DeepSeek V4 liefern hervorragende Leistungen. Ich überlege bereits, mein Claude-Abo nächsten Monat zu kündigen. Und einige Experten in meinem Umfeld haben es bereits ausprobiert.

Aber zurück zum Thema: Einige von euch fragen sich wahrscheinlich: Was bedeuten Input, Output und Cache eigentlich?
Lassen Sie uns zunächst erklären, was ein Cache-Treffer bedeutet.
Hier eine Analogie: Du gehst zu deinem üblichen Nudelladen und bestellst zum ersten Mal „Rindfleisch-Ziehnudeln mit Ei, kein Koriander“. Der Besitzer muss das Rindfleisch frisch schneiden, den Teig kneten, das Ei kochen und die Zutaten vorbereiten – der ganze Vorgang dauert eine Weile. Zehn Minuten später kommt dein Freund und bestellt genau dasselbe. Der Besitzer sieht, dass die Zutaten noch heiß im Topf sind und die Nudeln aus derselben Charge stammen, also serviert er sie direkt – das ist ein „Treffer“.
Wenn die KI deine Eingabe verarbeitet, muss sie im Wesentlichen den gesamten von dir gesendeten Text „durchkauen“ (einschließlich System-Prompts, Gesprächsverlauf und deiner aktuellen Frage) und in einen internen Zwischenzustand für das Modell umwandeln. Dieser Schritt ist wirklich rechenintensiv.
Wenn die KI feststellt, dass der von dir diesmal gesendete Inhalt ein großes Anfangssegment hat, das exakt mit dem vorherigen übereinstimmt, verwendet sie direkt den Zwischenzustand vom letzten Mal, ohne ihn erneut durchkauen zu müssen – das ist ein Cache-Treffer.
Beachte drei wichtige Punkte:
- Muss eine exakte Präfix-Übereinstimmung sein. Selbst wenn du ein zusätzliches Leerzeichen einfügst oder am Anfang ein Satzzeichen änderst, wird der Cache ungültig und es beginnt von vorne.
- Hat eine zeitliche Begrenzung. Sie variiert je nach Anbieter. Zum Beispiel beträgt die Standardeinstellung von Anthropic nur 5 Minuten (läuft ab, während du auf der Toilette bist). Wenn du die 1-Stunden-Option möchtest, musst du extra bezahlen (2x der Basis-Input-Preis). DeepSeek’s Cache hält von einigen Stunden bis zu einigen Tagen.
- Gleiches Gespräch führt natürlicherweise zu Treffern. Denn mit jeder weiteren Runde in einem Gespräch ist die neue Eingabe = gesamter bisheriger Verlauf + Antwort der KI + deine neue Frage. Der große vorhergehende Verlauf ist exakt gleich, also trifft es natürlicherweise.
Ob der Cache trifft oder nicht, beeinflusst den Preis erheblich. Deshalb empfehle ich, nur verwandte Inhalte innerhalb desselben Gesprächs zu besprechen – nicht nur wegen des Kontextgedächtnisses, sondern auch wegen der Cache-Treffer. Ein neues Gespräch zu beginnen bedeutet, von vorne zu bezahlen, während das Fortsetzen des Gesprächs einen Rabatt bedeutet.
Die Bedeutungen von „pro Million Tokens Input (Cache-Treffer)“, „pro Million Tokens Input (Cache-Fehltreffer)“ und „pro Million Tokens Output“ sind also:
Pro Million Tokens Input (Cache-Fehltreffer): Der Teil des von dir diesmal gesendeten Inhalts, den die KI nicht aus vorherigen Berechnungen wiederverwenden kann und von Grund auf neu durchkauen muss, wird zu diesem Preis abgerechnet. Dies umfasst Erstgespräche, neue Sitzungen oder geänderte Prompts am Anfang.
Pro Million Tokens Input (Cache-Treffer): Der Teil des von dir diesmal gesendeten Inhalts, bei dem das Anfangssegment zufällig exakt mit einem vorherigen übereinstimmt und von der KI direkt wiederverwendet wird, wird zu diesem (viel günstigeren) Preis abgerechnet. Im selben Gespräch fallen die Verläufe ab der zweiten, dritten Runde usw. in diese Kategorie.
Pro Million Tokens Output: Die von der KI generierte Antwort wird zu diesem Preis abgerechnet. Dies ist immer am teuersten, da „Generieren“ mehr Rechenleistung verbraucht als „Verstehen“ – bei einem entwirft die KI wiederholt, wählt Wörter aus und bildet Sätze im Kopf, während bei der anderen die KI nur das Material durchgeht.
Lassen Sie uns ein konkretes Beispiel verwenden, um ein Gefühl dafür zu bekommen. Angenommen, du verwendest DeepSeek, um ein 3000-Token-Stück Code zu ändern:
- Erste Frage: Input 3000 Tokens (alle Fehltreffer) + KI-Output 500 Tokens
- Dann frage „Kann das noch optimiert werden?“: Input wird über 3500 Tokens (davon 3500 vorheriger Verlauf, alle Cache-Treffer; nur die paar Dutzend neuen Wörter, die du hinzugefügt hast, zählen als Fehltreffer) + KI-Output 600 Tokens
- Ein neues Gespräch beginnen, den Code erneut einfügen und dieselbe Frage stellen: Wieder 3000 Tokens alle Fehltreffer
Wenn der Fehltreffer-Preis das 10-fache des Treffer-Preises beträgt, kann der Kostenunterschied allein für den Input zwischen „eine Folgefrage im selben Gespräch stellen“ und „ein neues Gespräch beginnen, um erneut zu fragen“ fast das 10-fache betragen.
Diesmal hat DeepSeek also den Cache-Treffer-Preis auf ein Zehntel des ursprünglichen Preises gesenkt, kombiniert mit dem 75% Rabatt auf das Pro-Modell. Für Anwendungsfälle mit langen Kontexten + mehreren Gesprächsrunden (wie Programmieren, Dokumentenanalyse, lange Chats) ist das fast ein knochenbrechender Preisnachlass. Wenn du Skills geschrieben oder Automatisierungs-Workflows eingerichtet hast, weißt du, dass das wiederholte Aufrufen eines langen Prompts die Norm ist. Die tatsächlichen Einsparungen durch diese Preissenkung sind noch dramatischer, als sie auf dem Papier erscheinen.
Abschließend ein praktischer Tipp: Gewöhne dir an, ein Thema im selben Gespräch abzuschließen, bevor du ein neues beginnst. Mach nicht ständig „alles löschen und neu anfangen“. Die KI wird sich nicht nur an dich erinnern, sondern du sparst auch Geld.
Zusammenfassung
Was wir heute gelernt haben:
- Was ist ein Cache-Treffer — Die KI speichert die Eingabe, die sie beim letzten Mal durchgekaut hat. Wenn der Anfang diesmal gleich ist, verwendet sie sie direkt wieder, spart Rechenleistung, und der Preis wird entsprechend reduziert.
- Drei wichtige Bedingungen — Muss eine exakte Präfix-Übereinstimmung sein, hat eine zeitliche Begrenzung (variiert von Minuten bis Tagen je nach Anbieter), und gleiches Gespräch führt natürlicherweise zu Treffern.
- Worauf sich die drei Preise beziehen — Cache-Fehltreffer = neu berechneter Input; Cache-Treffer = wiederverwendeter Input (günstigster); Output = KI-generierte Antwort (teuerster).
- Warum Output am teuersten ist — „Generieren“ verbraucht mehr Rechenleistung als „Verstehen“; die KI entwirft wiederholt im Kopf, und der Preis ist normalerweise ein Vielfaches des Input-Fehltreffer-Preises.
Wichtige Erkenntnisse:
- Fortsetzen im selben Gespräch bedeutet automatische Rabatte; häufiges Beginnen neuer Gespräche bedeutet jedes Mal den vollen Preis zu zahlen.
- Ändere Prompts am Ende; wenn du den Anfang änderst, wird der Cache ungültig.
- Szenarien mit langem Kontext + mehreren Gesprächsrunden (Programmieren, Dokumentenanalyse, lange Chats) profitieren am meisten. DeepSeek’s Preissenkungen sind für solche Nutzer im Grunde knochenbrechend.