DeepSeek has finally released the V4 model. I’ve been trying it out these past few days and it feels great, especially the Flash model with its excellent cost-performance ratio. My own expense tracking mini-program originally had a response time of 5 seconds, but now it’s down to 2.5 seconds. In a word: smooth!
The only downside is that the Pro model isn’t very cheap. According to the official website, prices will drop further once domestic chip supply ramps up in the second half of the year.
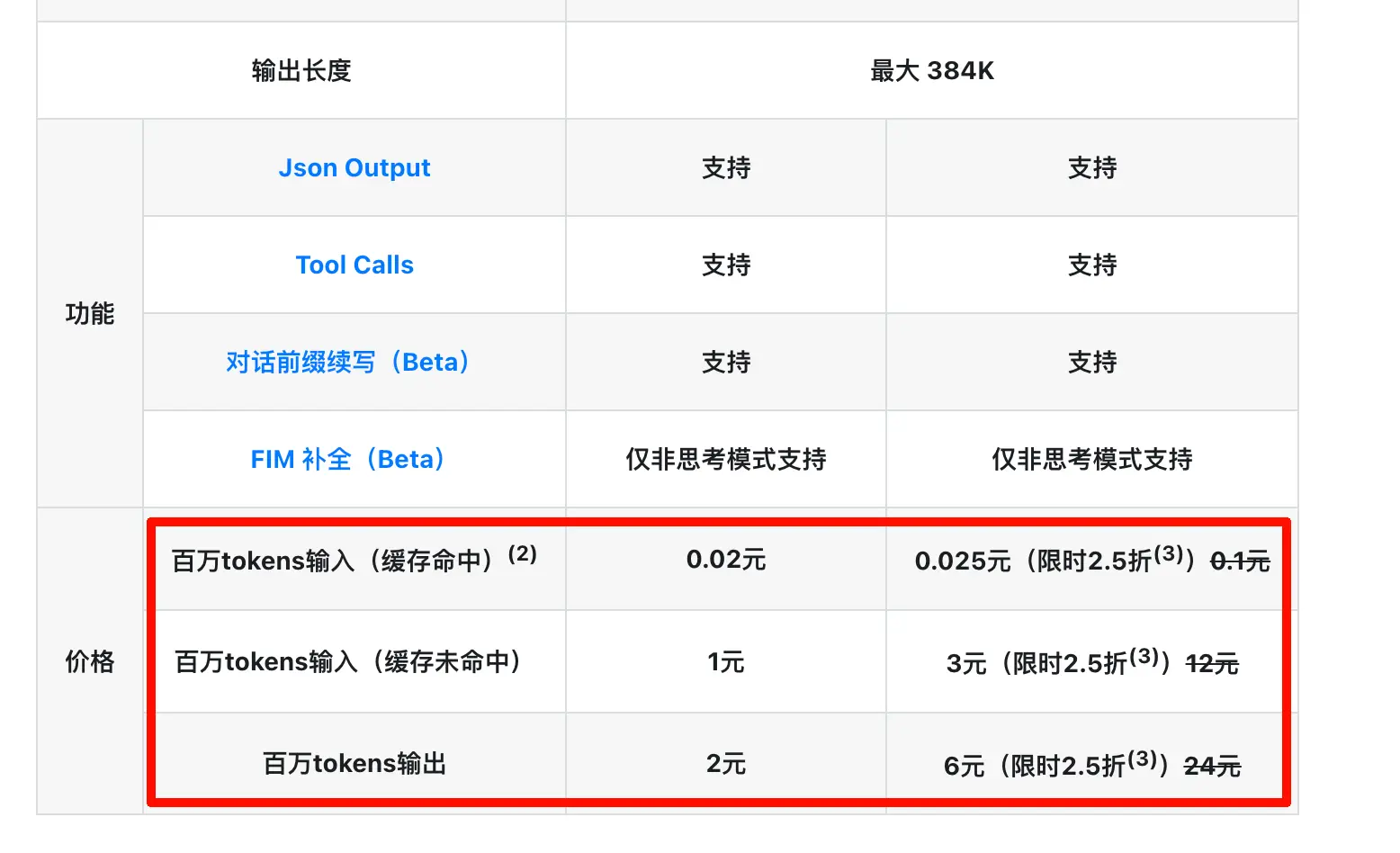
Unexpectedly, two days later the Pro model got a limited-time 75% discount (and I suspect this discount might be long-term). Yesterday, they also reduced the cache hit price to one-tenth of the original! What more can I say? Time to stand up and pedal hard!
This is the DeepSeek we know! A few days ago I was criticizing certain Coding Plans for being hard to get and having poor experiences. DeepSeek seems to be directly lowering the overall API price to below that of Coding Plans. Especially now that many Coding Plans prohibit use outside of programming, DeepSeek’s sincerity stands out even more.
Some Coding Plans’ APIs might ban you if you integrate translation, but DeepSeek doesn’t care—use it however you like.
GPT-5.5 and DeepSeek V4 are performing excellently. I’m already considering canceling my Claude subscription next month. And some experts around me have already tried it.

But getting back to the point, some of you are probably wondering: what do input, output, and cache actually mean?
Let’s first introduce what a cache hit means.
Here’s an analogy: You go to your usual noodle shop and order “beef pulled noodles with egg, no cilantro” for the first time. The owner has to slice the beef fresh, knead the dough, boil the egg, and prepare the ingredients—the whole process takes a while. Ten minutes later, your friend arrives and orders the exact same thing. The owner sees that the ingredients are still hot in the pot and the noodles are from the same batch, so he serves it directly—that’s a “hit”.
When AI processes your input, it essentially has to “chew through” all the text you send (including system prompts, conversation history, and your current question) and convert it into an internal intermediate state for the model. This step is truly computationally intensive.
If the AI finds that the content you sent this time has a large initial segment that is exactly the same as the previous one, it directly reuses the intermediate state from last time without having to chew through it again—that’s a cache hit.
Note three key points:
- Must be an exact prefix match. Even if you add an extra space or change a punctuation mark at the beginning, the cache is invalidated, and it starts from scratch.
- Has a time limit. It varies by provider. For example, Anthropic’s default is only 5 minutes (expires while you’re in the bathroom). If you want the 1-hour option, you have to pay extra (2x the base input price). DeepSeek’s cache lasts from a few hours to a few days.
- Same conversation naturally tends to hit. Because with each additional turn in a conversation, the new input = all previous history + AI’s response + your new question. The large preceding history is exactly the same, so it naturally hits.
Whether the cache hits or not greatly affects the price. That’s why I recommend discussing only related content within the same conversation—not just for context memory, but also because it affects cache hits. Starting a new conversation means paying from scratch, while continuing the conversation means getting a discount.
So, the meanings of “per million tokens input (cache hit)”, “per million tokens input (cache miss)”, and “per million tokens output” are:
Per million tokens input (cache miss): The part of the content you send this time that the AI cannot reuse from previous calculations and must chew through from scratch is priced at this rate. This includes first-time chats, new sessions, or changed prompts at the beginning.
Per million tokens input (cache hit): The part of the content you send this time where the beginning segment happens to be exactly the same as a previous instance and is directly reused by the AI is priced at this (much cheaper) rate. In the same conversation, the history from the second, third rounds, etc., falls into this category.
Per million tokens output: The response generated by the AI is priced at this rate. This is always the most expensive because “generation” consumes more computing power than “understanding”—one involves the AI repeatedly drafting, selecting words, and forming sentences in its mind, while the other involves the AI just reviewing the material.
Let’s use a concrete example to get a feel. Suppose you’re using DeepSeek to modify a 3000-token piece of code:
- First question: Input 3000 tokens (all miss) + AI output 500 tokens
- Then ask “Can this be optimized further?”: Input becomes over 3500 tokens (of which 3500 is previous history, all cache hit; only the few dozen new words you added count as miss) + AI output 600 tokens
- Start a new conversation, paste the code again, and ask the same question: Another 3000 tokens all miss
If the miss price is 10 times the hit price, then the cost difference for just the input between “asking a follow-up in the same conversation” and “starting a new conversation to ask again” can be nearly 10 times.
So this time DeepSeek has slashed the cache hit price to one-tenth of the original, combined with the 75% discount on the Pro model. For use cases with long contexts + multi-turn conversations (like coding, document analysis, long chats), this is almost a bone-breaking price cut. If you’ve written Skills or set up automation workflows, you know that repeatedly calling a long prompt is the norm. The actual savings from this price reduction are even more dramatic than they appear on paper.
Finally, a practical tip: Develop the habit of finishing a topic within the same conversation before starting a new one. Don’t just “clear and start fresh” all the time. Not only will the AI remember you, but it will also save you money.
Summary
What we learned today:
- What is a cache hit — The AI stores the input it chewed through last time. If the beginning is the same this time, it directly reuses it, saving computational power, and the price is discounted accordingly.
- Three key conditions — Must be an exact prefix match, has a time limit (varies from minutes to days across providers), and same conversation naturally tends to hit.
- What the three prices refer to — Cache miss = input that is recalculated; cache hit = reused input (cheapest); output = AI-generated response (most expensive).
- Why output is the most expensive — “Generation” consumes more computing power than “understanding”; the AI repeatedly drafts in its mind, and the price is usually several times that of input miss.
Key takeaways:
- Continuing in the same conversation means automatic discounts; starting new conversations frequently means paying full price every time.
- Modify prompts at the end; if you change the beginning, the cache is invalidated.
- Long context + multi-turn conversation scenarios (coding, document analysis, long chats) benefit the most. DeepSeek’s price cuts are essentially bone-breaking for such users.