DeepSeek finalmente ha lanzado el modelo V4. Lo he estado probando estos últimos días y se siente genial, especialmente el modelo Flash con su excelente relación calidad-precio. Mi propio miniprograma de seguimiento de gastos originalmente tenía un tiempo de respuesta de 5 segundos, pero ahora ha bajado a 2.5 segundos. En una palabra: ¡fluido!
La única desventaja es que el modelo Pro no es muy barato. Según el sitio web oficial, los precios bajarán aún más cuando aumente el suministro de chips nacionales en la segunda mitad del año.
Inesperadamente, dos días después, el modelo Pro obtuvo un descuento del 75% por tiempo limitado (y sospecho que este descuento podría ser a largo plazo). Ayer, también redujeron el precio de acierto de caché a una décima parte del original! ¿Qué más puedo decir? ¡Es hora de ponerse de pie y pedalear fuerte!
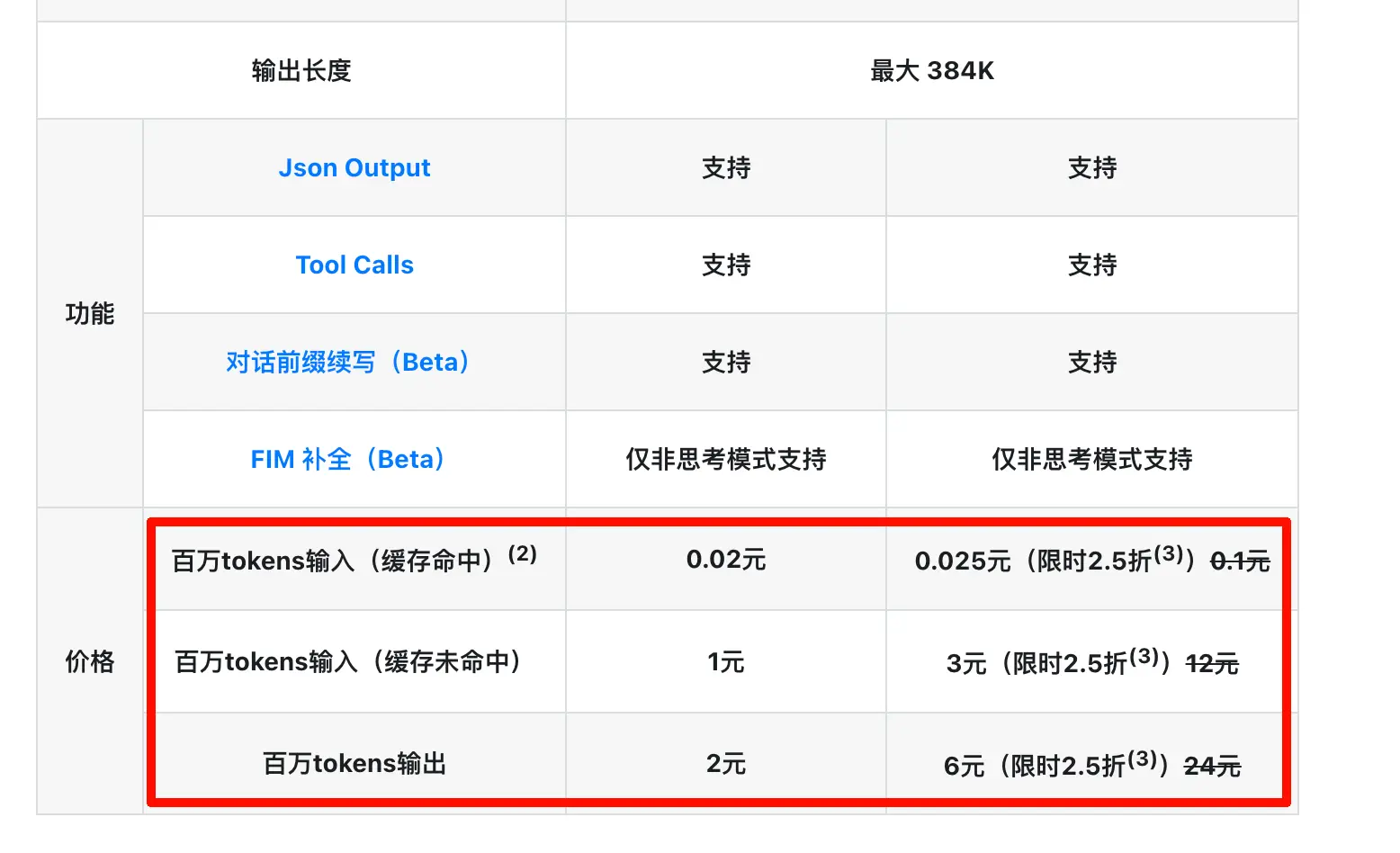
¡Este es el DeepSeek que conocemos! Hace unos días estaba criticando ciertos Planes de Codificación por ser difíciles de obtener y tener malas experiencias. DeepSeek parece estar bajando directamente el precio general de la API por debajo del de los Planes de Codificación. Especialmente ahora que muchos Planes de Codificación prohíben su uso fuera de la programación, la sinceridad de DeepSeek destaca aún más.
Algunas APIs de Planes de Codificación podrían prohibirte si integras traducción, pero a DeepSeek no le importa, úsalo como quieras.
GPT-5.5 y DeepSeek V4 están funcionando excelentemente. Ya estoy considerando cancelar mi suscripción a Claude el próximo mes. Y algunos expertos a mi alrededor ya lo han probado.

Pero volviendo al tema, algunos de ustedes probablemente se preguntan: ¿qué significan realmente entrada, salida y caché?
Primero, introduzcamos qué significa un acierto de caché.
Aquí hay una analogía: Vas a tu tienda de fideos habitual y pides “fideos tirados con carne de res, con huevo, sin cilantro” por primera vez. El dueño tiene que cortar la carne de res fresca, amasar la masa, hervir el huevo y preparar los ingredientes; todo el proceso lleva un tiempo. Diez minutos después, llega tu amigo y pide exactamente lo mismo. El dueño ve que los ingredientes todavía están calientes en la olla y los fideos son del mismo lote, así que los sirve directamente: eso es un “acierto”.
Cuando la IA procesa tu entrada, esencialmente tiene que “masticar” todo el texto que envías (incluyendo prompts del sistema, historial de conversación y tu pregunta actual) y convertirlo en un estado intermedio interno para el modelo. Este paso es realmente intensivo en cómputo.
Si la IA encuentra que el contenido que enviaste esta vez tiene un gran segmento inicial que es exactamente igual al anterior, reutiliza directamente el estado intermedio de la última vez sin tener que masticarlo de nuevo: eso es un acierto de caché.
Nota tres puntos clave:
- Debe ser una coincidencia exacta de prefijo. Incluso si agregas un espacio extra o cambias un signo de puntuación al principio, la caché se invalida y comienza desde cero.
- Tiene un límite de tiempo. Varía según el proveedor. Por ejemplo, el valor predeterminado de Anthropic es solo 5 minutos (caduca mientras estás en el baño). Si quieres la opción de 1 hora, tienes que pagar extra (2x el precio base de entrada). La caché de DeepSeek dura desde unas horas hasta unos días.
- La misma conversación tiende naturalmente a acertar. Porque con cada turno adicional en una conversación, la nueva entrada = todo el historial anterior + respuesta de la IA + tu nueva pregunta. El gran historial precedente es exactamente el mismo, por lo que naturalmente acierta.
Si la caché acierta o no afecta enormemente el precio. Por eso recomiendo discutir solo contenido relacionado dentro de la misma conversación, no solo por la memoria de contexto, sino también porque afecta los aciertos de caché. Iniciar una nueva conversación significa pagar desde cero, mientras que continuar la conversación significa obtener un descuento.
Entonces, los significados de “por millón de tokens de entrada (acierto de caché)”, “por millón de tokens de entrada (fallo de caché)” y “por millón de tokens de salida” son:
Por millón de tokens de entrada (fallo de caché): La parte del contenido que envías esta vez que la IA no puede reutilizar de cálculos anteriores y debe masticar desde cero se cobra a esta tarifa. Esto incluye chats por primera vez, nuevas sesiones o prompts cambiados al principio.
Por millón de tokens de entrada (acierto de caché): La parte del contenido que envías esta vez donde el segmento inicial resulta ser exactamente igual a una instancia anterior y es reutilizado directamente por la IA se cobra a esta tarifa (mucho más barata). En la misma conversación, el historial de la segunda, tercera rondas, etc., entra en esta categoría.
Por millón de tokens de salida: La respuesta generada por la IA se cobra a esta tarifa. Siempre es la más cara porque “generar” consume más potencia de cómputo que “comprender”: una implica que la IA redacta, selecciona palabras y forma oraciones repetidamente en su mente, mientras que la otra implica que la IA solo revisa el material.
Usemos un ejemplo concreto para tener una idea. Supongamos que estás usando DeepSeek para modificar un fragmento de código de 3000 tokens:
- Primera pregunta: Entrada de 3000 tokens (todo fallo) + salida de la IA de 500 tokens
- Luego preguntas “¿Se puede optimizar esto más?”: La entrada se vuelve más de 3500 tokens (de los cuales 3500 son historial anterior, todo acierto de caché; solo las pocas docenas de palabras nuevas que agregaste cuentan como fallo) + salida de la IA de 600 tokens
- Inicias una nueva conversación, pegas el código de nuevo y haces la misma pregunta: Otros 3000 tokens, todo fallo
Si el precio de fallo es 10 veces el precio de acierto, entonces la diferencia de costo solo para la entrada entre “preguntar un seguimiento en la misma conversación” e “iniciar una nueva conversación para preguntar de nuevo” puede ser casi 10 veces.
Así que esta vez DeepSeek ha reducido el precio de acierto de caché a una décima parte del original, combinado con el descuento del 75% en el modelo Pro. Para casos de uso con contextos largos + conversaciones de múltiples turnos (como codificación, análisis de documentos, chats largos), esto es casi una reducción de precio que rompe huesos. Si has escrito Skills o configurado flujos de trabajo de automatización, sabes que llamar repetidamente a un prompt largo es la norma. El ahorro real de esta reducción de precio es aún más dramático de lo que parece en el papel.
Finalmente, un consejo práctico: Desarrolla el hábito de terminar un tema dentro de la misma conversación antes de iniciar una nueva. No siempre “limpies y empieces de nuevo”. No solo la IA te recordará, sino que también te ahorrará dinero.
Resumen
Lo que aprendimos hoy:
- Qué es un acierto de caché — La IA almacena la entrada que masticó la última vez. Si el principio es el mismo esta vez, lo reutiliza directamente, ahorrando potencia de cómputo, y el precio se descuenta en consecuencia.
- Tres condiciones clave — Debe ser una coincidencia exacta de prefijo, tiene un límite de tiempo (varía de minutos a días según el proveedor), y la misma conversación tiende naturalmente a acertar.
- A qué se refieren los tres precios — Fallo de caché = entrada que se recalcula; acierto de caché = entrada reutilizada (más barata); salida = respuesta generada por la IA (más cara).
- Por qué la salida es la más cara — “Generar” consume más potencia de cómputo que “comprender”; la IA redacta repetidamente en su mente, y el precio suele ser varias veces el del fallo de entrada.
Conclusiones clave:
- Continuar en la misma conversación significa descuentos automáticos; iniciar nuevas conversaciones con frecuencia significa pagar el precio completo cada vez.
- Modifica los prompts al final; si cambias el principio, la caché se invalida.
- Los escenarios de contexto largo + conversación de múltiples turnos (codificación, análisis de documentos, chats largos) son los más beneficiados. Los recortes de precios de DeepSeek son esencialmente demoledores para tales usuarios.