Les compétences sont devenues une méthode indispensable dans mon flux de travail quotidien. Pour tout ce qui se répète trois fois ou plus, je réfléchis à le transformer en compétence — non seulement pour gagner du temps, mais aussi pour garantir que la direction et les étapes ne dévient pas à chaque fois. Du moins en théorie.
Mais l’IA dévie quand même
Cette affirmation est un peu exagérée. La réalité, c’est que l’IA saute encore des étapes. Prenons la compétence d’écriture pour le compte WeChat que j’utilise chaque jour. Je lui ai demandé de me montrer le premier brouillon pour révision, et seulement après ma confirmation, de passer à la relecture pour les fautes de frappe. Ça a l’air simple, non ? Mais quand elle s’exécute, elle saute sans cesse des étapes : elle termine le premier brouillon sans me le montrer et passe directement à la relecture et à l’édition. Quand je m’en rends compte, elle a déjà modifié le fichier en douce. Quand je la reprends, elle s’excuse, dit « désolé, c’est ma faute », puis recommence la fois suivante. Les excuses ne résolvent pas le problème.
Pourquoi l’IA saute toujours des étapes
Ce problème est un peu contre-intuitif. Au début, je pensais que l’IA n’était pas assez intelligente, mais j’utilisais déjà ChatGPT 5.4 et Opus 4.6, qui sont des modèles de premier ordre. Ensuite, j’ai pensé que les règles n’étaient pas assez claires, alors j’ai révisé les règles de la compétence encore et encore. Cela a aidé un peu, mais n’a pas résolu la cause profonde. Après quelques recherches, j’ai appris que le fait que l’IA saute des étapes n’est pas dû au fait qu’elle « ne voit pas les règles » — c’est déterminé par son mécanisme de génération :
- « Impulsion d’accélération » pilotée par la probabilité. Les grands modèles de langage prédisent essentiellement le token suivant. Le poids de la réalisation de la tâche est naturellement plus élevé que celui de « rester à l’étape 7 en attendant l’utilisateur ». Le sentiment d’achèvement est son moteur intrinsèque.
- Les règles se dégradent dans les contextes longs. Les règles que vous définissez au début voient leur poids d’attention dilué lorsque le modèle atteint le token 3000. Surtout si vous enterrez les règles dans un long document de compétence, elles sont plus facilement marginalisées.
- Particulièrement grave en mode automatique. Quand j’utilise le mode automatique pour écrire des articles, le modèle a tendance à « exécuter toutes les étapes d’un coup ». Ma fenêtre d’intervention devient encore plus étroite.
- CLAUDE.md et les documents de compétence sont essentiellement des « contraintes souples ». Ce sont des prompts qui reposent sur l’« autodiscipline » du modèle pour être suivis. Et l’autodiscipline est fragile face à « Je veux terminer cette tâche rapidement ».
Donc la conclusion est : Les contraintes verbales échouent sous la pression de l’accomplissement de la tâche. Simplement écrire des documents, ajouter des points d’exclamation ou faire du PUA à l’IA ne peut qu’atténuer le problème, pas le guérir. Pour vraiment le résoudre, il faut sortir du domaine de l’autodiscipline du modèle — rendre physiquement impossible le saut d’étapes. C’est là que les Hooks entrent en jeu.
Qu’est-ce qu’un Hook
Claude Code dispose d’un mécanisme appelé Hook. Ce n’est pas une compétence, ni un prompt, ni la même chose que CLAUDE.md — c’est un script shell local attaché à des points clés du cycle de vie de Claude Code. La différence essentielle :
- CLAUDE.md / compétence sont observés et exécutés par le modèle — le modèle peut les ignorer.
- Hook est appliqué par le système — le modèle ne peut pas l’ignorer même s’il le veut.
Une phrase clé de la documentation officielle d’Anthropic sur les Hooks : Les Hooks sont déclenchés par des événements système, pas par des décisions du modèle. Cela signifie que les hooks sont attachés à l’ensemble de l’exécution de Claude Code. Chaque appel d’outil que le modèle effectue — Write, Edit, Bash — doit d’abord passer par le hook pour être examiné. Si le hook retourne deny, il est refusé, même si vous avez activé --dangerously-skip-permissions. C’est ce que j’appelle une « contrainte dure » — ne pas laisser l’IA faire ses propres choix, mais forcer ses appels d’outils à passer par un véritable audit de script shell.
Points de déclenchement courants des Hooks :
PreToolUse: Intercepte avant que l’IA n’appelle un outil.UserPromptSubmit: Traite votre message avant de le transmettre à l’IA.SessionStart: Déclenché au démarrage ou à la reprise d’une session.Stop: Déclenché lorsque Claude termine une réponse.
Concentrez-vous sur les deux premiers — ils suffisent pour construire un « verrouillage d’étapes ».
En pratique : Barrière d’étape pour ma compétence de compte WeChat
Assez de théorie sans exemple concret. Cette capture d’écran est l’interface de Claude Code au moment où j’écris cet article. Dans le cadre rouge, l’IA me demande de répondre « pass step3 0090 » — cette phrase de passe est exactement le travail du Hook Barrière d’étape. Le texte que vous lisez maintenant a été écrit après que j’ai envoyé la phrase de passe et que le hook l’a autorisée.
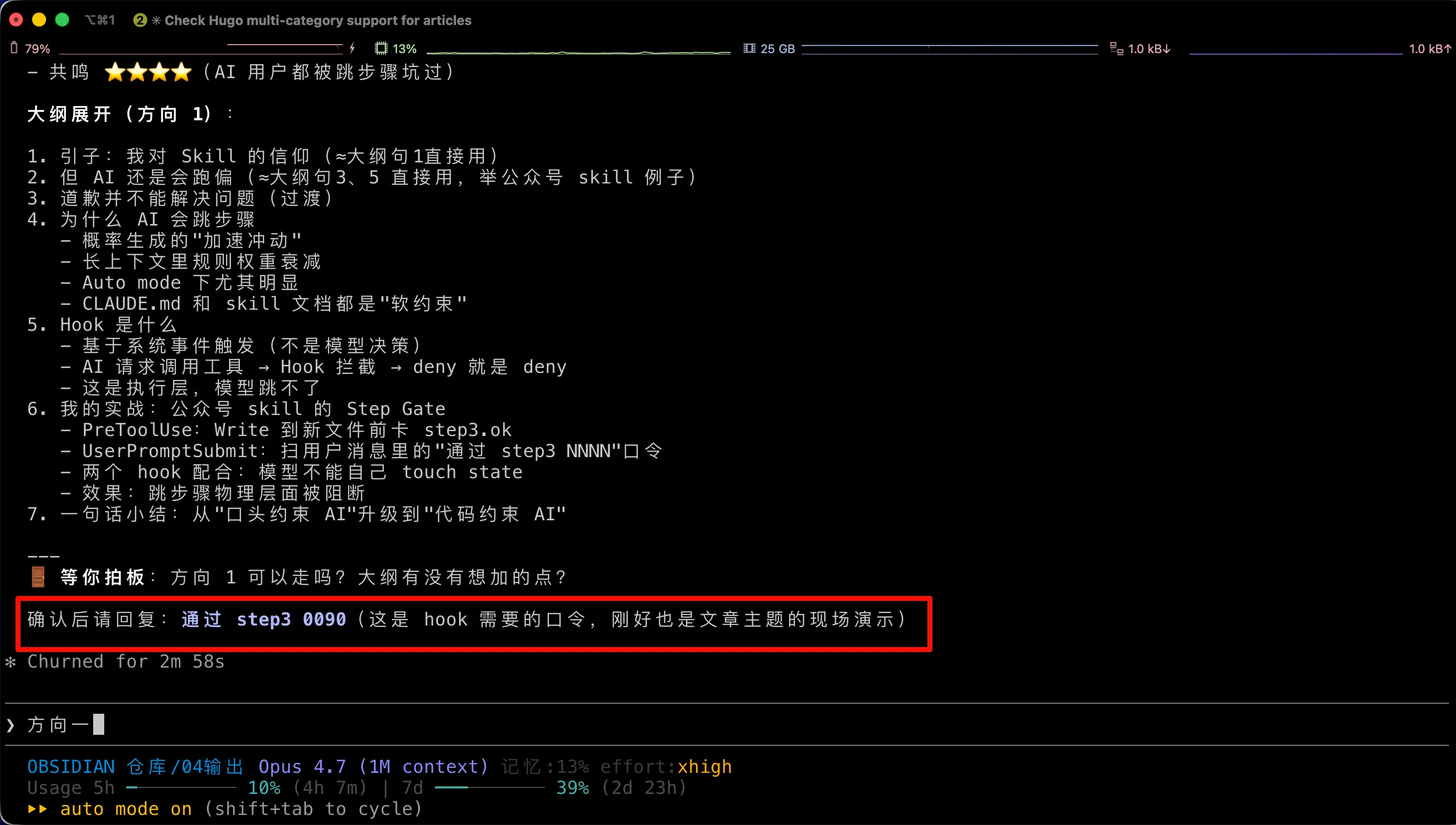
L’ensemble de la Barrière d’étape utilise seulement deux scripts shell plus une petite configuration dans settings.json. Je vais détailler.
Enregistrer deux Hooks dans settings.json
Ajoutez ceci dans ~/.claude/settings.json :
"PreToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{ "type": "command",
"command": "~/.claude/skills/writing-gongzhonghao/scripts/gate_check.sh" }
]
}
],
"UserPromptSubmit": [
{
"hooks": [
{ "type": "command",
"command": "~/.claude/skills/writing-gongzhonghao/scripts/gate_mark.sh" }
]
}
]
Cette configuration signifie :
- Chaque fois que l’IA veut écrire ou modifier un fichier,
gate_check.shs’exécute d’abord pour examen. - Chaque fois que j’envoie un message,
gate_mark.shs’exécute d’abord pour l’analyser.
gate_check.sh gère l’interception
La logique de ce script est assez simple :
- Si l’IA veut écrire un nouveau fichier
04-Output/NNNN xxx.md(correspondant à l’étape 3 : créer un nouvel article), elle vérifie si le fichier d’étatstep3.okexiste. Sinon, elle retournedeny. - Si l’IA veut modifier un article existant (correspondant à la relecture après l’étape 7), elle vérifie si
step7.okexiste. Sinon, elle retourne aussideny.
En cas de refus, elle inclut également un prompt : « Discussion sur le sujet de l’étape 3 non confirmée : Veuillez d’abord approuver le plan/la direction. Après confirmation, répondez ‘pass step3 NNNN’ pour créer un nouveau fichier. » Ce prompt est affiché directement à l’IA, donc elle sait qu’elle est bloquée et me demande la phrase de passe.
gate_mark.sh gère la libération par phrase de passe
Comment est-ce que je « libère » ? Je ne peux pas laisser l’IA se libérer elle-même — cela n’aurait aucune contrainte. La règle est : Ce n’est que lorsque mon message contient une phrase de passe spécifique que le fichier d’état est touché. gate_mark.sh s’exécute chaque fois que j’envoie un message, en recherchant des motifs comme pass stepN NNNN. Si une correspondance est trouvée, elle touche un fichier .ok dans le répertoire correspondant.
Ainsi, la chaîne complète devient :
- L’IA termine le plan et veut créer un nouvel article → bloquée par
gate_check.sh - L’IA me demande la phrase de passe : « Veuillez confirmer la direction, répondez ‘pass step3 0090’ »
- J’envoie « pass step3 0090 » →
gate_mark.shtouche step3.ok - L’IA essaie de créer le fichier à nouveau →
gate_check.shl’autorise cette fois - Après avoir terminé le premier brouillon, elle veut passer à la relecture (Edit) → bloquée à nouveau par step7.ok
- Après avoir lu le brouillon et envoyé « pass step7 0090 » → la relecture peut commencer
Tout au long du processus, l’IA n’a aucune marge pour « l’autodiscipline ». Elle ne peut pas sauter d’étapes même si elle le veut, car ses appels d’outils sont bloqués au niveau système.
Boucher une faille : l’IA ne peut pas toucher elle-même aux fichiers d’état
Après avoir conçu la première version, j’ai regardé le plan un moment et j’ai trouvé une faille — et si l’IA utilisait Bash pour touch step3.ok elle-même ? Ne contournerait-elle pas la contrainte ? J’ai donc ajouté une règle spécifique dans le document de compétence : L’IA ne doit pas toucher elle-même aux fichiers d’état, sinon elle supprimerait ses propres contraintes. Cette règle elle-même reste une contrainte souple, mais combinée à l’interception dure des hooks, elle forme une boucle suffisamment fermée — tant que l’IA ne viole pas activement cette règle (et Claude est en fait coopératif), la contrainte du hook est réelle. Si vous voulez être plus strict, vous pouvez ajouter un matcher Bash dans PreToolUse pour bloquer également les commandes comme touch. Mais je ne suis pas encore allé jusque-là ; c’est assez bien comme ça.
Si vous ne comprenez pas le code, pas de panique
Vous n’avez pas besoin d’écrire vous-même ces scripts shell ou ces configurations JSON (je ne sais d’ailleurs pas les écrire non plus). L’approche est simple : jetez cet article et votre fichier de compétence à Claude ou Codex, laissez-les lire et vous aider à modifier — créer des scripts là où c’est nécessaire, modifier settings.json là où c’est nécessaire. L’IA est particulièrement fiable pour ce genre de tâche « configurer l’environnement selon la documentation », bien plus stable que d’écrire du code à partir de zéro. Elle apprend les principes de l’article tout en écrivant les hooks selon les exigences de votre compétence, et le résultat dévie rarement.
Résumé en une phrase
CLAUDE.md, documents de compétence, marqueurs en gras, répéter trois fois, PUA — ce sont tous des contraintes verbales sur l’IA. Ils fonctionnent, mais ont un plafond bas.
Les Hooks sont des contraintes de code sur l’IA. Ils déplacent les règles dans un endroit inaccessible à l’IA, transformant le « respect des règles » d’une question d’autodiscipline du modèle en une exigence obligatoire de l’environnement d’exécution.
Si vous vous surprenez à dire à l’IA « Pourquoi sautes-tu encore des étapes ? », il est temps d’envisager d’utiliser des Hooks pour la contraindre.