DeepSeek a enfin publié le modèle V4. Je l’essaie depuis quelques jours et c’est génial, surtout le modèle Flash avec son excellent rapport qualité-prix. Mon mini-programme de suivi des dépenses avait un temps de réponse de 5 secondes, maintenant il est descendu à 2,5 secondes. En un mot : fluide !
Le seul inconvénient, c’est que le modèle Pro n’est pas très bon marché. D’après le site officiel, les prix baisseront encore une fois que l’approvisionnement en puces nationales augmentera au second semestre.
De manière inattendue, deux jours plus tard, le modèle Pro a bénéficié d’une réduction limitée de 75 % (et je soupçonne que cette réduction pourrait être à long terme). Hier, ils ont également réduit le prix du cache hit à un dixième du prix d’origine ! Que dire de plus ? Il est temps de se lever et de pédaler fort !
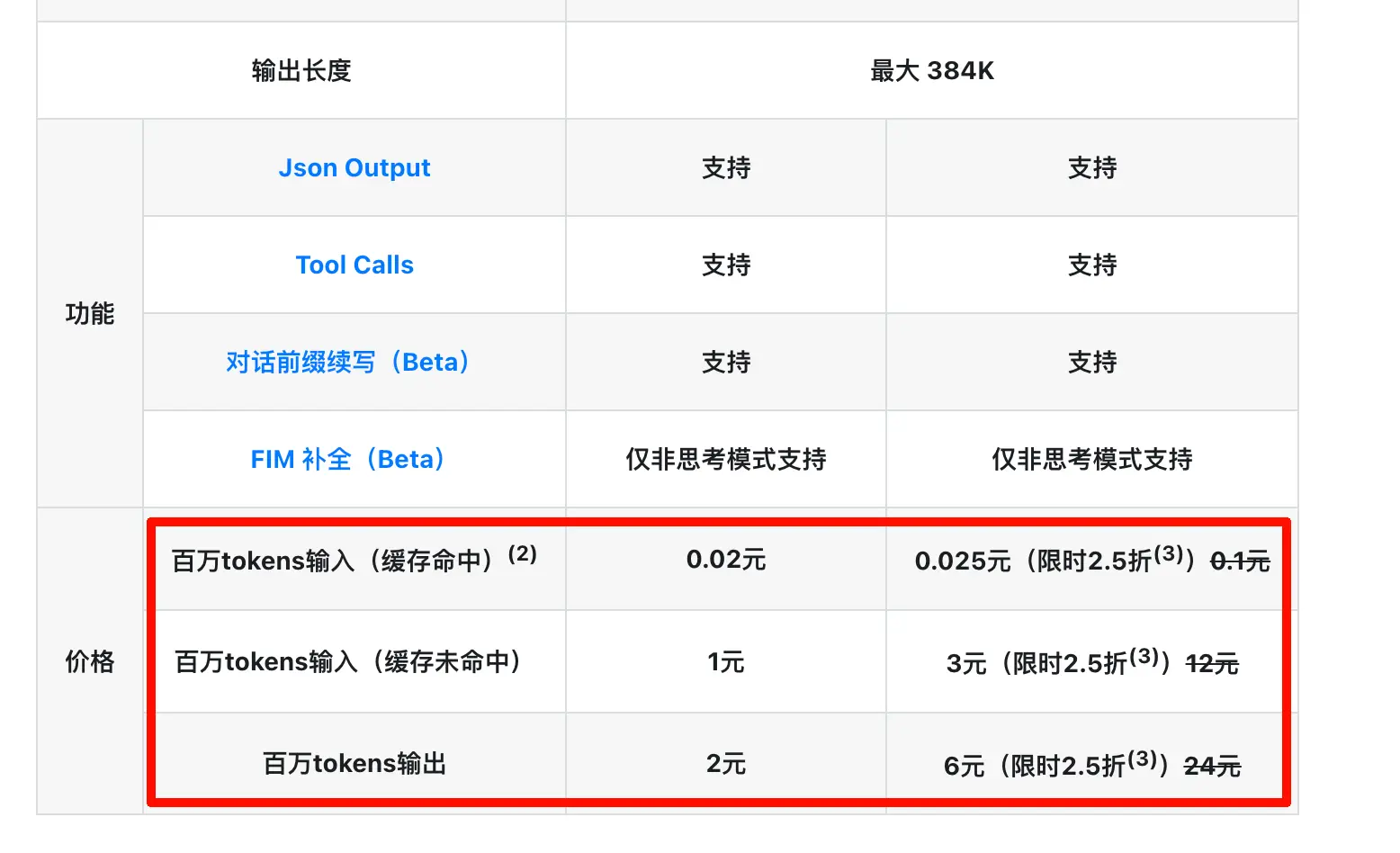
C’est le DeepSeek que nous connaissons ! Il y a quelques jours, je critiquais certains Coding Plans pour leur difficulté d’accès et leur mauvaise expérience. DeepSeek semble baisser directement le prix global de l’API en dessous de celui des Coding Plans. Surtout que maintenant, de nombreux Coding Plans interdisent l’utilisation en dehors de la programmation, la sincérité de DeepSeek ressort encore plus.
Certaines API de Coding Plans pourraient vous bannir si vous intégrez une traduction, mais DeepSeek s’en fiche, utilisez-les comme vous voulez.
GPT-5.5 et DeepSeek V4 fonctionnent de manière excellente. J’envisage déjà d’annuler mon abonnement à Claude le mois prochain. Et certains experts autour de moi l’ont déjà essayé.

Mais revenons au sujet, certains d’entre vous se demandent probablement : que signifient réellement input, output et cache ?
Commençons par expliquer ce qu’est un cache hit.
Voici une analogie : Vous allez dans votre restaurant de nouilles habituel et commandez pour la première fois « des nouilles tirées au bœuf avec un œuf, sans coriandre ». Le propriétaire doit trancher le bœuf frais, pétrir la pâte, faire bouillir l’œuf et préparer les ingrédients – tout le processus prend du temps. Dix minutes plus tard, votre ami arrive et commande exactement la même chose. Le propriétaire voit que les ingrédients sont encore chauds dans la casserole et que les nouilles sont du même lot, alors il les sert directement – c’est un « hit ».
Quand l’IA traite votre entrée, elle doit essentiellement « mâcher » tout le texte que vous envoyez (y compris les instructions système, l’historique de la conversation et votre question actuelle) et le convertir en un état intermédiaire interne pour le modèle. Cette étape est vraiment gourmande en calcul.
Si l’IA constate que le contenu que vous avez envoyé cette fois a un grand segment initial exactement identique au précédent, elle réutilise directement l’état intermédiaire de la dernière fois sans avoir à le mâcher à nouveau – c’est un cache hit.
Notez trois points clés :
- Doit être une correspondance exacte du préfixe. Même si vous ajoutez un espace supplémentaire ou changez une ponctuation au début, le cache est invalidé et on repart de zéro.
- A une limite de temps. Cela varie selon le fournisseur. Par exemple, celui d’Anthropic n’est que de 5 minutes par défaut (expire pendant que vous êtes aux toilettes). Si vous voulez l’option 1 heure, vous devez payer un supplément (2x le prix de l’input de base). Le cache de DeepSeek dure de quelques heures à quelques jours.
- La même conversation tend naturellement à faire un hit. Car à chaque tour supplémentaire dans une conversation, la nouvelle entrée = tout l’historique précédent + la réponse de l’IA + votre nouvelle question. Le grand historique précédent est exactement le même, donc il fait naturellement un hit.
Que le cache fasse un hit ou non affecte grandement le prix. C’est pourquoi je recommande de discuter uniquement de contenu connexe dans la même conversation – non seulement pour la mémoire du contexte, mais aussi parce que cela affecte les hits du cache. Commencer une nouvelle conversation signifie payer depuis le début, tandis que continuer la conversation signifie bénéficier d’une réduction.
Ainsi, les significations de « par million de tokens en entrée (cache hit) », « par million de tokens en entrée (cache miss) » et « par million de tokens en sortie » sont :
Par million de tokens en entrée (cache miss) : La partie du contenu que vous envoyez cette fois que l’IA ne peut pas réutiliser à partir de calculs précédents et doit mâcher depuis le début est facturée à ce tarif. Cela inclut les premières discussions, les nouvelles sessions ou les instructions modifiées au début.
Par million de tokens en entrée (cache hit) : La partie du contenu que vous envoyez cette fois où le segment de départ se trouve être exactement le même qu’une instance précédente et est directement réutilisé par l’IA est facturée à ce tarif (beaucoup moins cher). Dans la même conversation, l’historique des deuxième, troisième tours, etc., entre dans cette catégorie.
Par million de tokens en sortie : La réponse générée par l’IA est facturée à ce tarif. C’est toujours le plus cher car la « génération » consomme plus de puissance de calcul que la « compréhension » – l’une implique que l’IA rédige, choisit des mots et forme des phrases à plusieurs reprises dans son esprit, tandis que l’autre implique que l’IA se contente de revoir le matériel.
Prenons un exemple concret pour mieux comprendre. Supposons que vous utilisiez DeepSeek pour modifier un morceau de code de 3000 tokens :
- Première question : 3000 tokens en entrée (tous en miss) + 500 tokens en sortie de l’IA
- Puis demandez « Peut-on optimiser davantage ? » : L’entrée devient plus de 3500 tokens (dont 3500 sont l’historique précédent, tous en cache hit ; seuls les quelques dizaines de nouveaux mots que vous avez ajoutés comptent comme miss) + 600 tokens en sortie de l’IA
- Commencez une nouvelle conversation, collez à nouveau le code et posez la même question : Encore 3000 tokens tous en miss
Si le prix du miss est 10 fois celui du hit, alors la différence de coût pour l’entrée entre « poser une question de suivi dans la même conversation » et « commencer une nouvelle conversation pour redemander » peut être presque 10 fois.
Donc cette fois, DeepSeek a réduit le prix du cache hit à un dixième du prix d’origine, combiné à la réduction de 75 % sur le modèle Pro. Pour les cas d’utilisation avec contextes longs + conversations à plusieurs tours (comme le codage, l’analyse de documents, les longues discussions), c’est presque une baisse de prix cassée. Si vous avez écrit des Skills ou configuré des flux d’automatisation, vous savez qu’appeler à plusieurs reprises une longue instruction est la norme. Les économies réelles de cette réduction de prix sont encore plus spectaculaires qu’elles n’y paraissent sur le papier.
Enfin, un conseil pratique : Prenez l’habitude de terminer un sujet dans la même conversation avant d’en commencer une nouvelle. Ne faites pas tout le temps « effacer et recommencer ». Non seulement l’IA se souviendra de vous, mais vous économiserez aussi de l’argent.
Résumé
Ce que nous avons appris aujourd’hui :
- Qu’est-ce qu’un cache hit — L’IA stocke l’entrée qu’elle a mâchée la dernière fois. Si le début est le même cette fois, elle le réutilise directement, économisant de la puissance de calcul, et le prix est réduit en conséquence.
- Trois conditions clés — Doit être une correspondance exacte du préfixe, a une limite de temps (varie de quelques minutes à quelques jours selon les fournisseurs), et la même conversation tend naturellement à faire un hit.
- Ce que signifient les trois prix — Cache miss = entrée recalculée ; cache hit = entrée réutilisée (la moins chère) ; sortie = réponse générée par l’IA (la plus chère).
- Pourquoi la sortie est la plus chère — La « génération » consomme plus de puissance de calcul que la « compréhension » ; l’IA rédige à plusieurs reprises dans son esprit, et le prix est généralement plusieurs fois celui de l’entrée en miss.
Points à retenir :
- Continuer dans la même conversation signifie des réductions automatiques ; commencer fréquemment de nouvelles conversations signifie payer le plein tarif à chaque fois.
- Modifiez les instructions à la fin ; si vous changez le début, le cache est invalidé.
- Les scénarios de contexte long + conversation à plusieurs tours (codage, analyse de documents, longues discussions) sont les plus avantageux. Les baisses de prix de DeepSeek sont essentiellement cassées pour ces utilisateurs.