Nous avons déjà abordé les modèles : utiliser des variables pour remplir automatiquement les dates et les titres, et appliquer des formats en un clic lors de la création de nouvelles notes. Passons maintenant à l’étape suivante.
Prendre des notes ne suffit pas. Chaque jour, vous naviguez sur Twitter, lisez des articles WeChat et parcourez Reddit. Quand vous trouvez quelque chose d’intéressant, comment le sauvegarder ? Une capture d’écran ? Cela devient une image, non recherchable. Copier-coller ? La mise en forme est un désastre, et vous devez ajouter manuellement le titre et le lien. Le jeter dans les favoris du navigateur ? C’est le cimetière éternel des signets : ça entre mais ne ressort jamais, et vous ne les regardez plus.
Ce chapitre résout ce problème : comment sauvegarder rapidement et proprement du contenu web dans Obsidian. L’outil est l’extension officielle du navigateur pour Obsidian — Web Clipper.
Pourquoi utiliser Web Clipper
Avant Web Clipper, j’ai traversé environ trois étapes pour sauvegarder des articles web :
Première étape : capture d’écran. Un clic, on jette ça dans les notes. Problème : les captures ne sont pas recherchables. Trois mois plus tard, vous n’avez aucune idée de ce que vous avez capturé, encore moins de le retrouver.
Deuxième étape : copier-coller. Copier le texte dans Obsidian, puis ajouter manuellement le titre et le lien source. Problème : la mise en forme est généralement déformée — les titres deviennent du texte brut, le gras disparaît, les blocs de code deviennent du texte simple. Il faut des minutes pour nettoyer à chaque fois.
Troisième étape : les favoris. Cliquer sur l’étoile dans le navigateur, le plus simple. Le coût : vous n’ouvrirez plus jamais ces liens.
La logique de Web Clipper : sauvegarde en un clic, mise en forme propre, métadonnées automatiques, directement dans Obsidian. Titre, lien d’origine, date de sauvegarde — tout est rempli automatiquement. Le contenu est au format Markdown, les images sont conservées. Avec l’Interpréteur IA, vous pouvez même faire résumer le contenu par l’IA lors de la capture.
Installation
Web Clipper est une extension de navigateur. Elle prend actuellement en charge Chrome, Edge, Firefox et Safari (certaines fonctionnalités peuvent différer).
Important : les articles WeChat doivent d’abord être ouverts dans un navigateur ; vous ne pouvez pas les utiliser directement dans le client WeChat. Le client WeChat est un environnement séparé auquel les extensions de navigateur n’ont pas accès. Vous devez copier le lien, l’ouvrir dans Chrome ou Edge, puis capturer.
Étapes d’installation
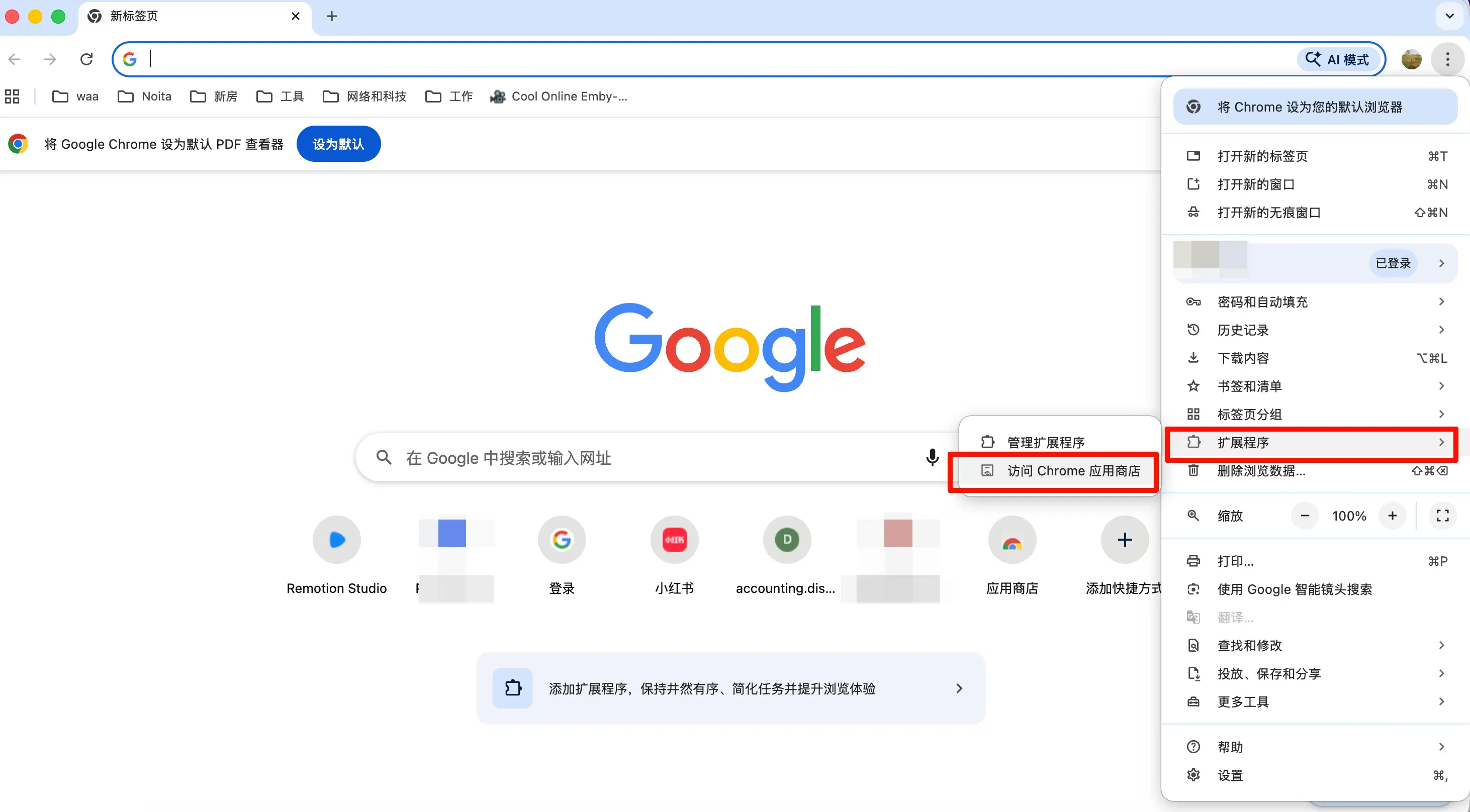
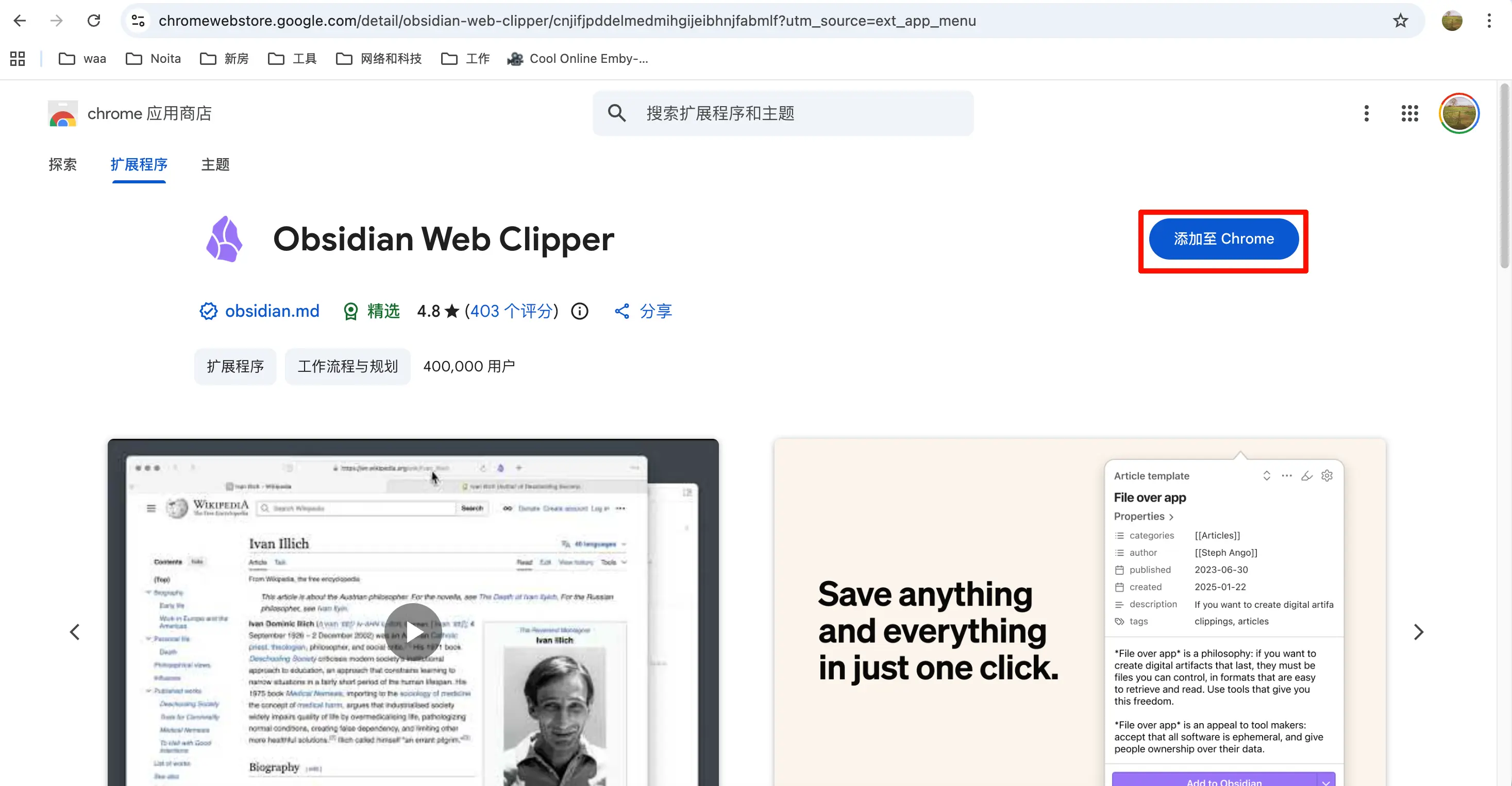
Étape 1 : Les utilisateurs de Chrome ouvrent le Chrome Web Store, recherchent “Obsidian Web Clipper”, trouvent l’extension officielle (icône identique à Obsidian, le motif gemme), cliquent sur “Ajouter à Chrome”.
Étape 2 : Les utilisateurs d’Edge ouvrent de même la boutique de modules complémentaires Edge, recherchent “Obsidian Web Clipper”, installent. Edge peut aussi utiliser la version du Chrome Web Store, les deux fonctionnent.
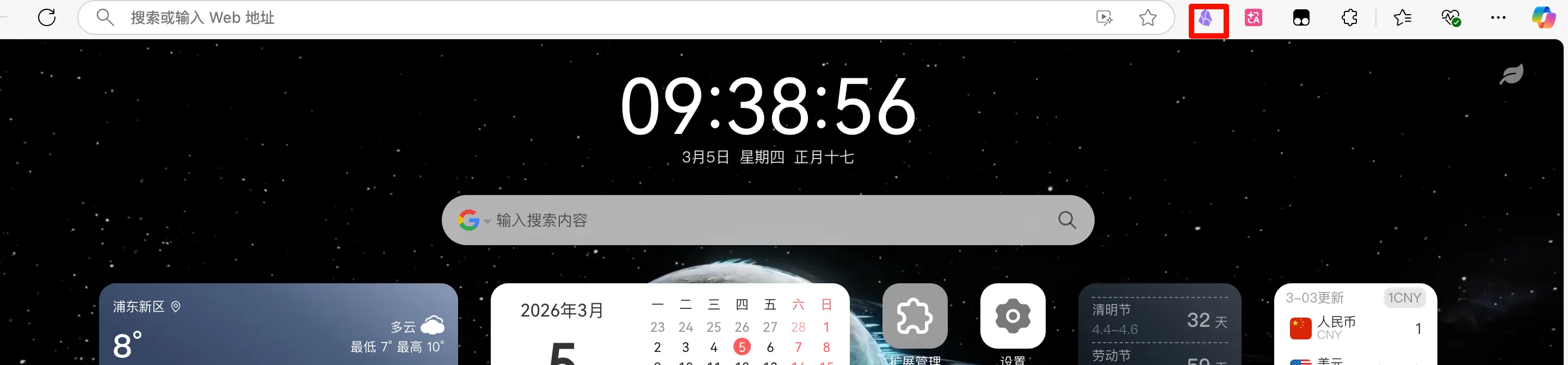
Étape 3 : Après installation, l’icône de l’extension apparaît dans la barre d’outils en haut à droite. Si elle n’est pas visible, cliquez sur l’icône en forme de puzzle (Extensions) tout à droite de la barre d’outils, trouvez Obsidian Web Clipper et épinglez-le à la barre d’outils.
Voilà pour l’installation.
Paramètres de base
Cliquez sur l’icône de l’extension dans la barre d’outils pour ouvrir le panneau de capture. Il y a une petite icône d’engrenage en bas à droite — c’est l’entrée des paramètres. Allez dans les paramètres et configurez les bases.
Connecter votre coffre Obsidian
La première chose dans les paramètres est de connecter votre Coffre. Dans la section “Coffres”, cliquez sur “Ajouter un coffre”, entrez le nom de votre coffre — celui affiché en bas à gauche d’Obsidian. Par exemple, mon coffre s’appelle “Obsidian Vault”, je saisis donc cela.
Remarque : lors de la première connexion, Obsidian affichera une fenêtre d’autorisation vous demandant si vous autorisez Web Clipper à y accéder. Sélectionnez “Autoriser” — c’est une invite de sécurité normale.
Définir le dossier de sauvegarde par défaut
Après avoir connecté le coffre, définissez l’Emplacement par défaut.
Il est recommandé de créer un dossier de boîte de réception dédié, comme 00-Inbox ou Inbox, spécifiquement pour le contenu capturé. Ne le jetez pas directement à la racine du coffre — avec le temps, la racine deviendra désordonnée et vous ne saurez plus quelles notes sont organisées et lesquelles sont des archives web non traitées.
Aperçu de l’interface
Après configuration, chaque fois que vous ouvrez l’extension, vous verrez trois zones principales :
- Haut : Zone des propriétés — identifie automatiquement le titre de la page actuelle, l’URL, l’auteur (si disponible)
- Milieu : Zone d’aperçu du contenu — le corps a été converti en Markdown
- Bas : Zone d’action — choisissez dans quel coffre et dossier sauvegarder, sélectionnez un modèle, puis cliquez sur “Capturer” pour sauvegarder
Interpréteur IA
C’est la fonctionnalité qui mérite le plus de temps de configuration dans Web Clipper.
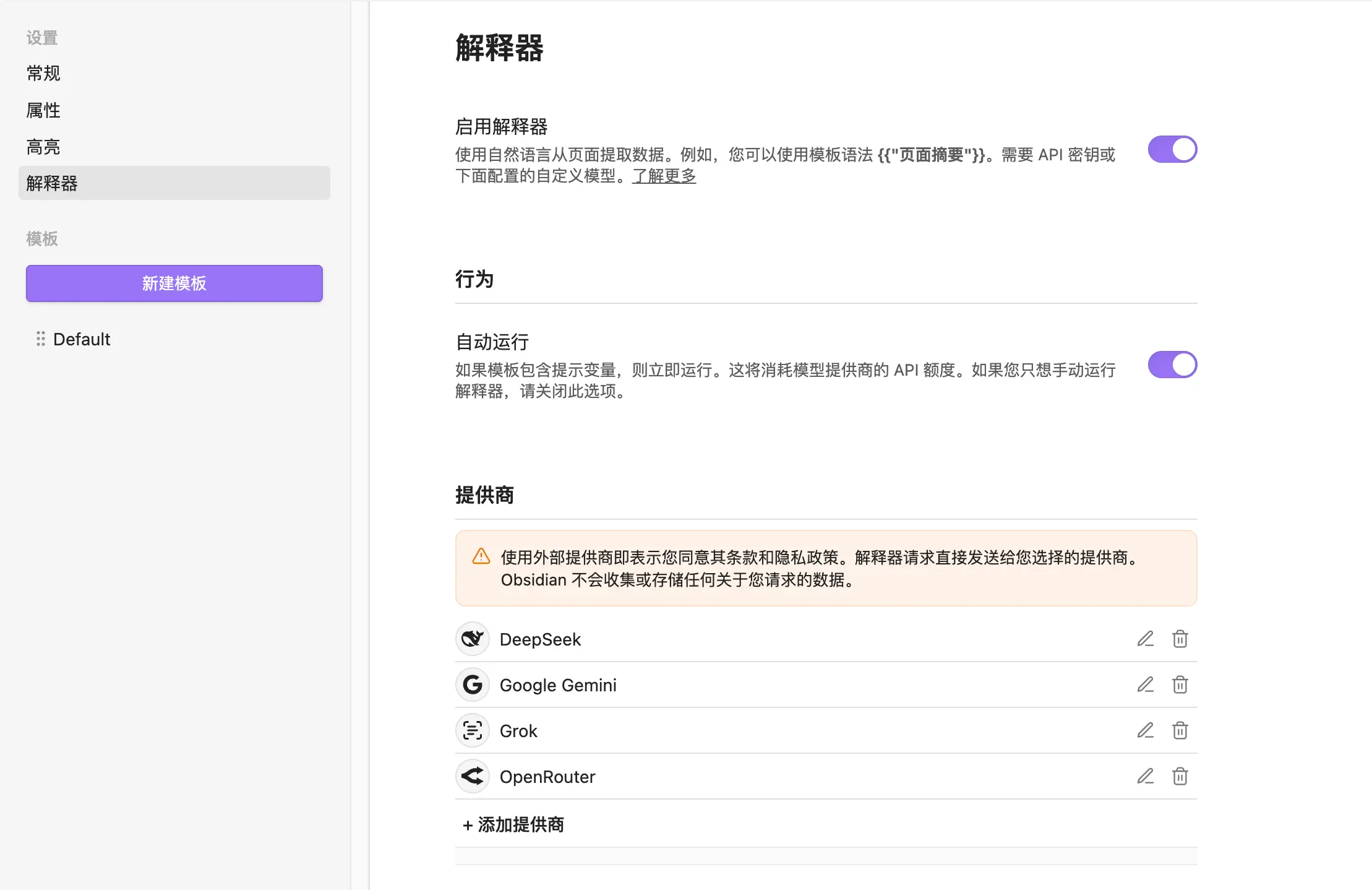
Qu’est-ce que c’est
L’Interpréteur IA vous permet d’écrire des instructions dans un modèle, et lors de la capture, cliquez sur le bouton “Ajouter à Obsidian”, et l’IA traitera le contenu spécifié. Par exemple : résumer le texte intégral, extraire des mots-clés, traduire… Ce qu’il peut faire dépend de la façon dont vous rédigez l’invite.
Cette fonctionnalité nécessite une Clé API. Si vous avez déjà une clé API d’OpenAI, DeepSeek ou Anthropic, vous pouvez l’utiliser directement ; sinon, inscrivez-vous sur la plateforme respective.
Configuration
Allez dans les paramètres, trouvez l’onglet “Interpréteur”.
Étape 1 : Sélectionnez votre source de modèle et entrez la clé API correspondante. Prend en charge OpenAI, Anthropic (Claude), Ollama (modèles locaux), et plus encore. J’utilise DeepSeek — je trouve qu’il est le meilleur pour résumer des articles.
Étape 2 : Activez “Activer l’interpréteur”, activez ce commutateur.
Ensuite, écrivez des variables d’invite dans votre modèle, et lors de la capture, une zone d’interpréteur apparaîtra dans la fenêtre de l’extension — cliquez pour la déclencher.
Créer des modèles personnalisés
Web Clipper est livré avec un modèle par défaut — il fonctionne, mais il n’est pas génial. Prenez quelques minutes pour créer votre propre modèle, et chaque capture sera bien plus agréable.
Pourquoi personnaliser les modèles
Différents types de contenu nécessitent des informations différentes :
- Articles techniques : vous voulez titre, lien, résumé IA, corps
- Articles WeChat : vous voulez titre, auteur, date de publication, résumé IA
- Pages produits : vous voulez titre, prix, lien, pas besoin du texte intégral
Un seul modèle ne peut pas couvrir tous les scénarios. Créez quelques modèles en fonction du type de contenu, et sélectionnez celui approprié lors de la capture — très pratique.
Accéder aux paramètres des modèles
Dans les paramètres de Web Clipper, cliquez sur “Nouveau modèle” à gauche pour en créer un nouveau. Je suis paresseux donc je n’en utilise qu’un seul.
Donnez un nom au modèle, comme “Collecte d’articles”, puis commencez à écrire le contenu.
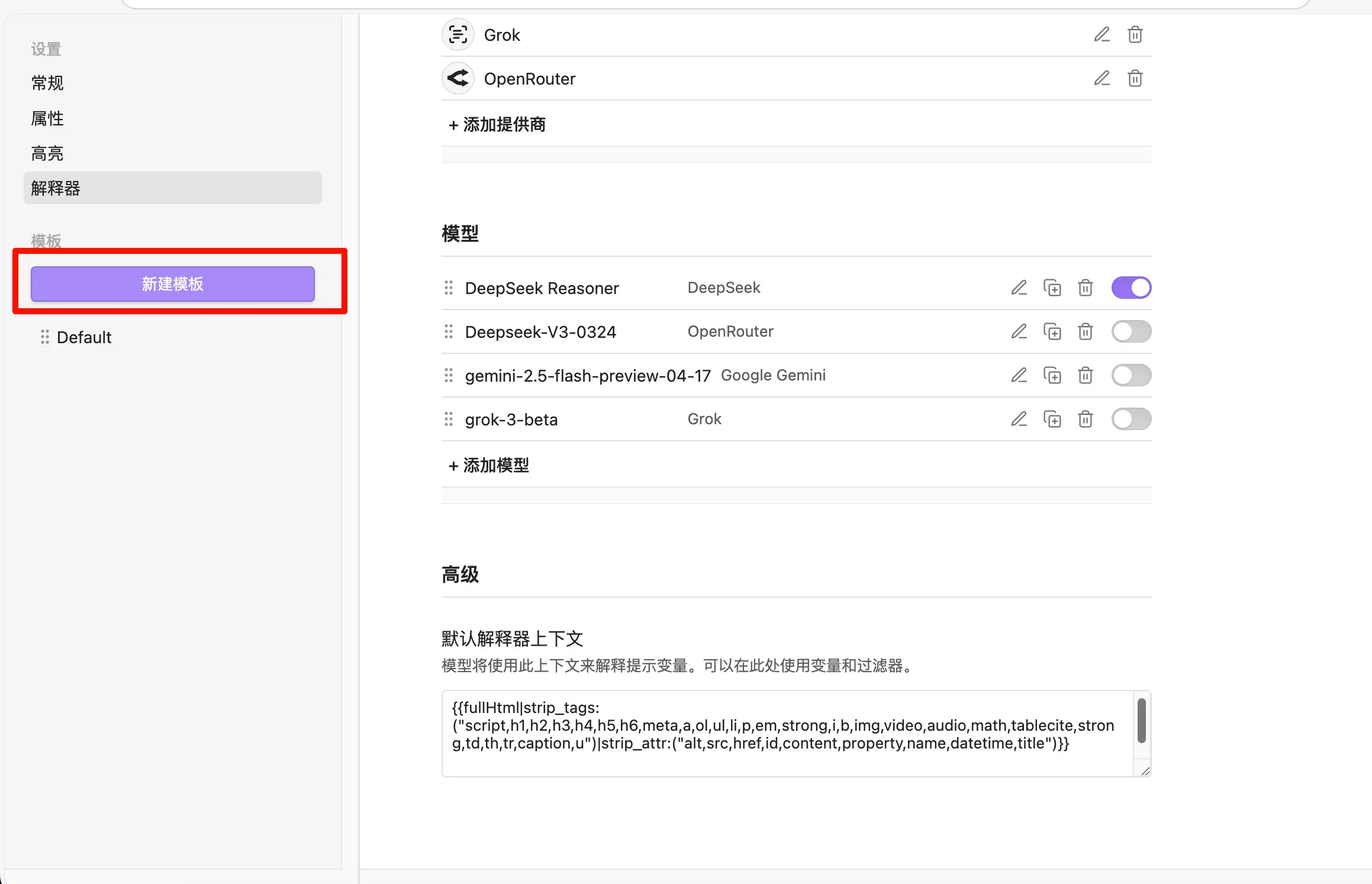
Variables de modèle
Web Clipper prend en charge deux types de variables :
Variables de page — extraites automatiquement de la page web actuelle :
| Variable | Description |
|---|---|
{{title}} |
Titre de la page |
{{url}} |
URL de la page actuelle |
{{author}} |
Auteur de l’article (si reconnu) |
{{date}} |
Date d’aujourd’hui |
{{content}} |
Contenu du corps (format Markdown) |
Variables d’interpréteur — appeler l’IA dans les propriétés ou le contenu :
La syntaxe de l’interpréteur est simple : mettez l’instruction que vous voulez donner à l’IA entre guillemets, entourée d’accolades doubles, comme ceci :
{{"Summarize the full article without using an H1 heading"}}
Le texte intérieur est votre instruction à l’IA ; le format extérieur {{" "}} ne doit pas être modifié. Web Clipper reconnaît cette syntaxe et sait qu’il doit appeler l’IA pour traitement lors de la capture.
Les propriétés et le contenu peuvent l’utiliser. Si vous voulez qu’un champ de propriété soit rempli automatiquement par l’IA, écrivez ce format dans la valeur de la propriété ; si vous voulez insérer un résumé IA dans le contenu, écrivez-le également là.
Exemple de modèle complet
Voici le modèle que j’utilise :
Propriétés du modèle :
URL: {{url}}
Saved: {{date}}
Contenu du modèle :
# Summary
Il y a une chose qui mérite d’être mentionnée : la ligne auteur utilise {{author|split:", "|wikilink|join}}, pas le simple {{author}}. C’est une combinaison variable + filtre — d’abord diviser le champ auteur par virgule (certains articles reconnaissent plusieurs auteurs), puis convertir chaque nom en format wiki-link Obsidian [[Nom de l'auteur]], et enfin les rejoindre. Ainsi, après la capture, cliquer sur le nom de l’auteur vous amène à la note correspondante. Vous n’êtes pas obligé d’utiliser cela ; {{author}} produisant du texte brut est parfaitement acceptable, selon votre préférence.
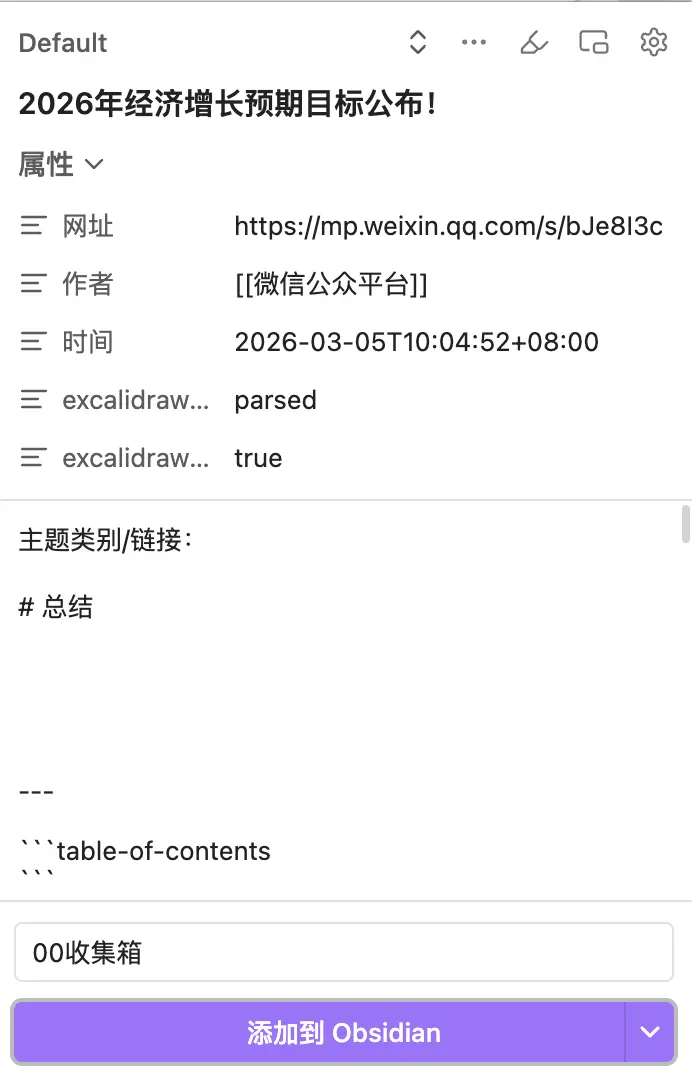
Pour la zone de contenu, je n’ai laissé que deux lignes vides : Catégorie de sujet/Lien pour ajouter manuellement des informations connexes, et # Résumé comme espace réservé de titre — si vous avez activé l’interpréteur, vous pouvez ajouter {{"Résumez l'article complet sans utiliser de titre H1"}} en dessous pour laisser l’IA remplir le contenu automatiquement ; sinon, vous pouvez écrire quelques phrases manuellement après la capture.
Pratique : Capturer un article
Tous les réglages sont faits, passons à l’utilisation réelle.
Supposons que vous voyez un article WeChat que vous aimez et que vous voulez le sauvegarder.
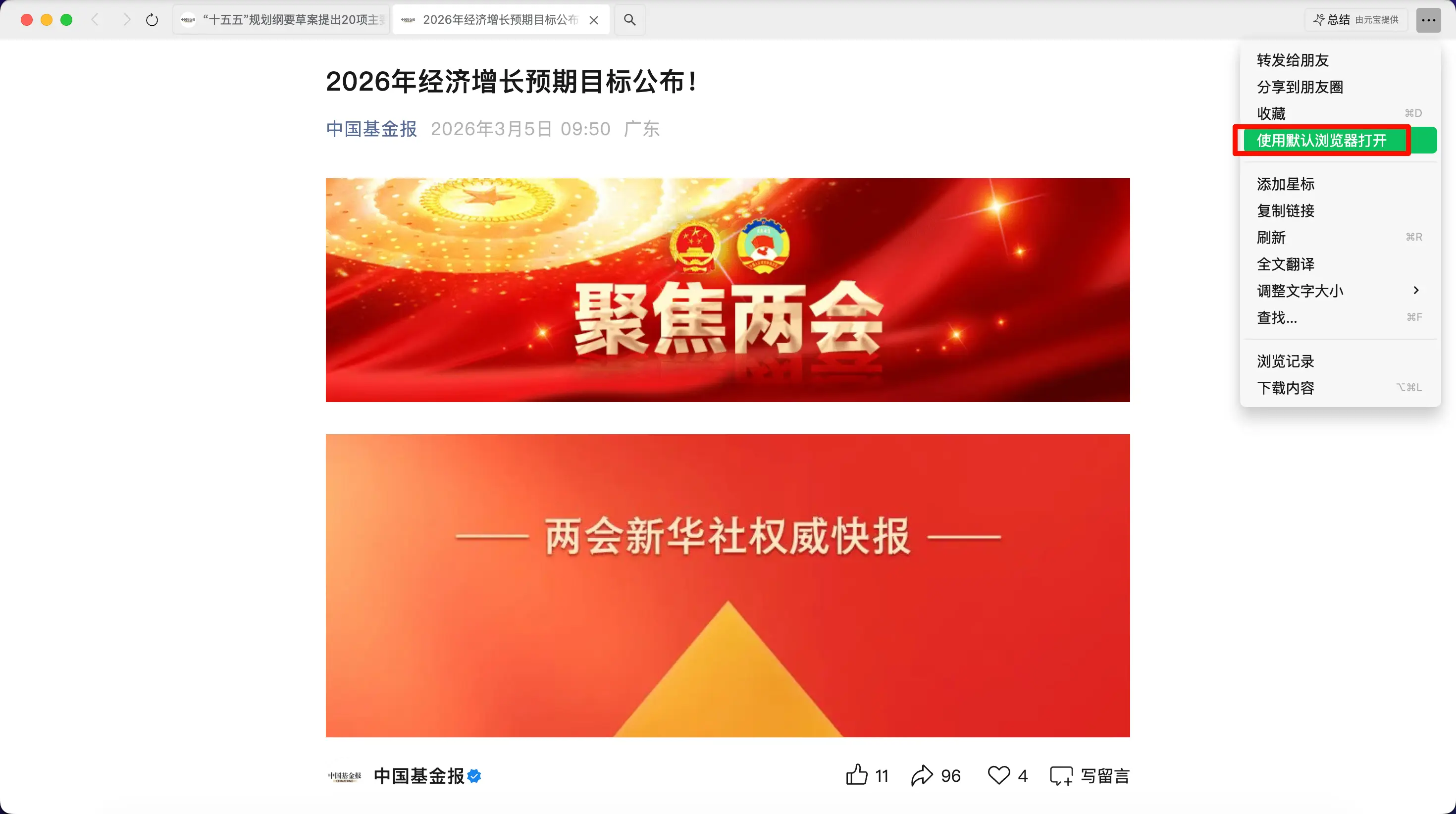
Étape 1 : Copiez le lien et ouvrez-le dans un navigateur. Dans l’article WeChat, appuyez sur le menu en haut à droite et sélectionnez “Ouvrir dans le navigateur par défaut”.
Étape 2 : Cliquez sur l’icône Web Clipper. L’icône gemme dans la barre d’outils en haut à droite, cliquez dessus pour ouvrir le panneau de capture.
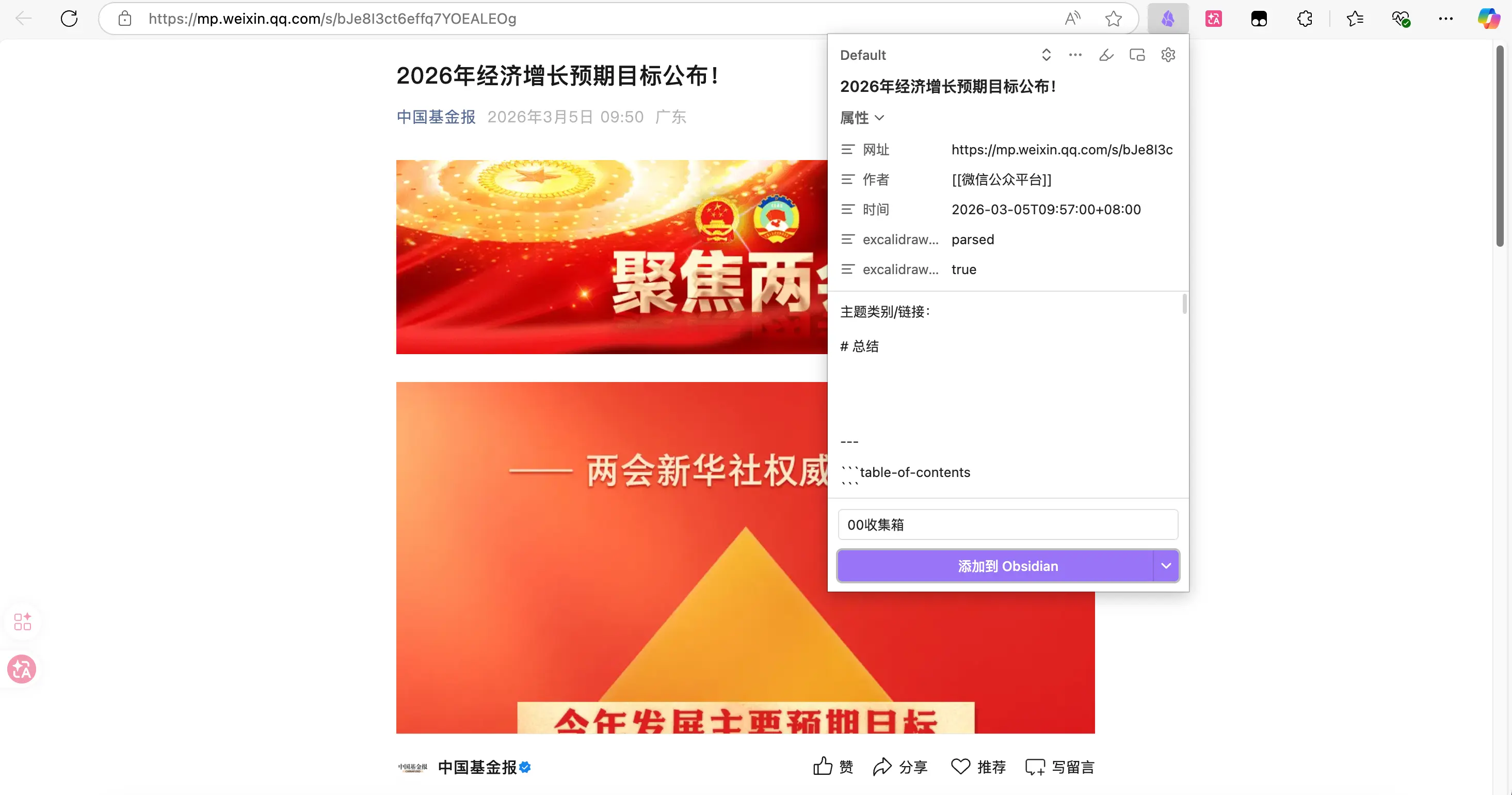
Étape 3 : Vérifiez les propriétés. Le panneau reconnaîtra automatiquement le titre et l’URL de l’article. Si le champ auteur n’est pas reconnu, remplissez-le manuellement. La date est celle d’aujourd’hui, pas besoin de la modifier.
Étape 4 : Sélectionnez un modèle. Choisissez le modèle “Collecte d’articles” que vous avez créé. Si vous avez activé l’interpréteur IA, vous verrez une animation de rotation — l’IA génère le résumé, attendez qu’elle termine.
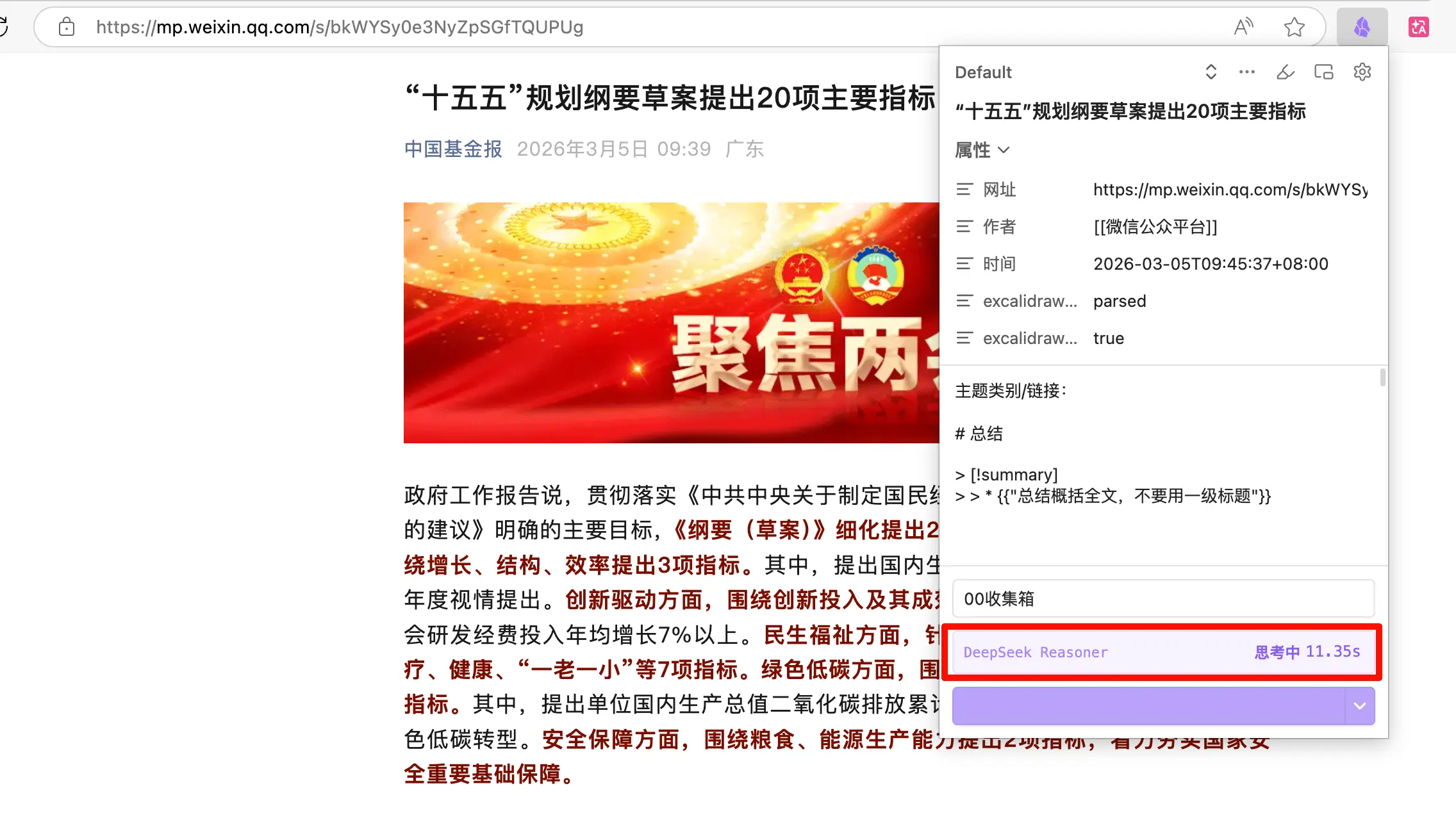
Étape 5 : Cliquez sur “Ajouter à Obsidian”. Une seconde plus tard, ouvrez Obsidian, allez dans votre dossier de boîte de réception, et l’article est là. Titre, lien, date, résumé IA — tout est présent, et le contenu est un Markdown propre.
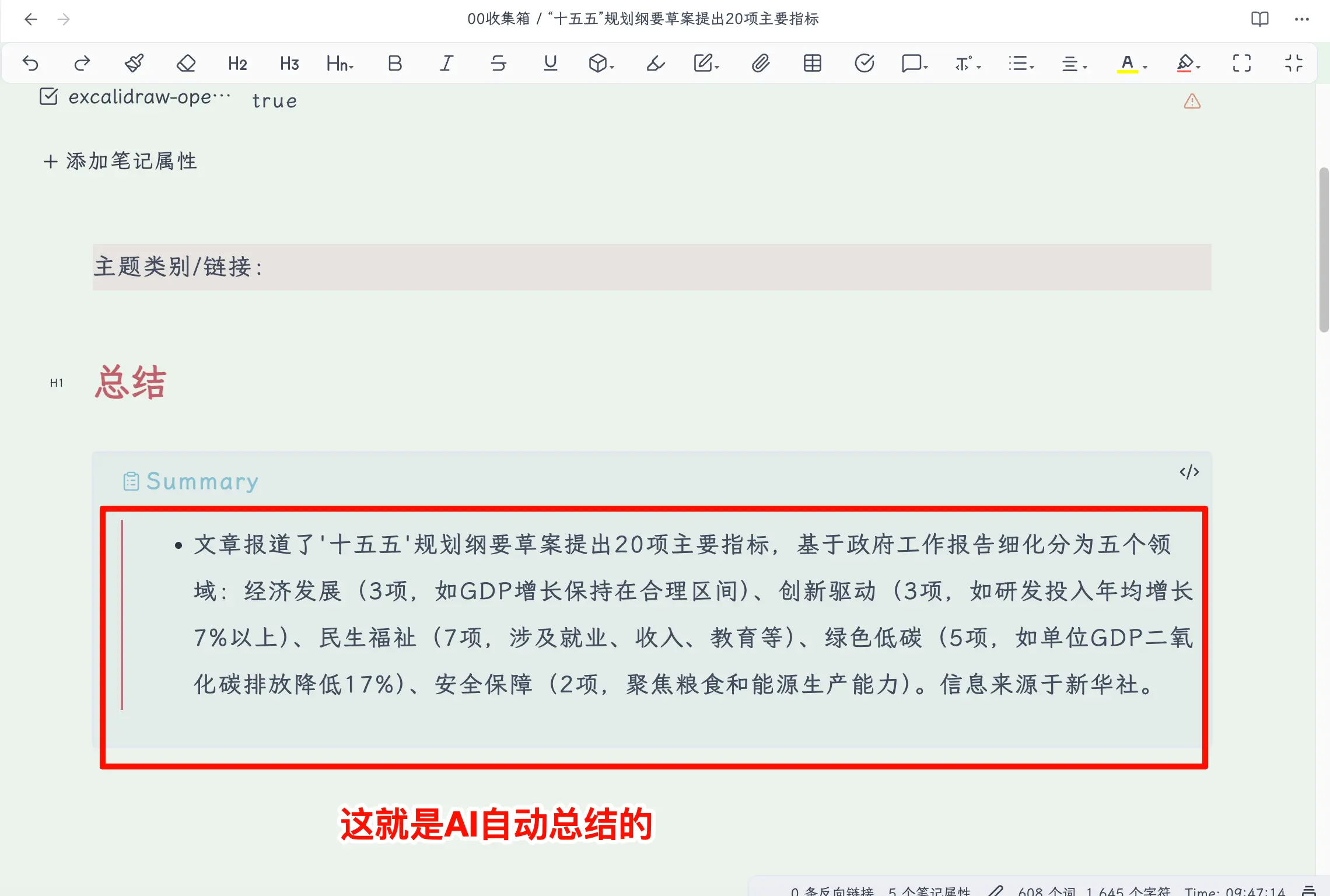
Résumé
Ce que vous avez appris aujourd’hui :
- Web Clipper est l’extension officielle du navigateur pour Obsidian qui sauvegarde les pages web sous forme de notes Obsidian en un clic, avec une mise en forme propre et des métadonnées automatiques.
- Les articles WeChat doivent être ouverts dans un navigateur pour être capturés ; ils ne peuvent pas être utilisés dans le client WeChat.
- L’Interpréteur IA nécessite une Clé API ; une fois configuré, il peut générer automatiquement des résumés et extraire des informations lors de la capture.
- Les modèles personnalisés = variables de propriétés + invites IA ; différents modèles pour différents types de contenu rendent la capture plus efficace.
Points clés :
- Créez un dossier de boîte de réception dédié ; ne jetez pas le contenu capturé directement à la racine du coffre.
- Faites d’abord fonctionner le flux de travail avec le modèle par défaut, puis prenez le temps de personnaliser — les modèles peuvent être modifiés à tout moment ; commencer est plus important.
- Les résumés IA sont un bonus, pas une nécessité — vous pouvez capturer normalement sans clé API ; vous manquez simplement l’étape de traitement IA.