DeepSeek akhirnya merilis model V4. Beberapa hari terakhir ini saya mencobanya dan rasanya sangat mantap, terutama model Flash dengan rasio harga-kinerja yang luar biasa. Mini-program pencatat pengeluaran saya sendiri yang awalnya waktu respons 5 detik, sekarang turun menjadi 2,5 detik. Singkatnya: mulus!
Satu-satunya kekurangan adalah model Pro tidak terlalu murah. Menurut situs resmi, harga akan turun lebih lanjut setelah pasokan chip dalam negeri meningkat di paruh kedua tahun ini.
Tak disangka, dua hari kemudian model Pro mendapat diskon 75% terbatas (dan saya curiga diskon ini mungkin jangka panjang). Kemarin, mereka juga menurunkan harga cache hit menjadi sepersepuluh dari harga semula! Apa lagi yang bisa saya katakan? Saatnya berdiri dan mengayuh sekuat tenaga!
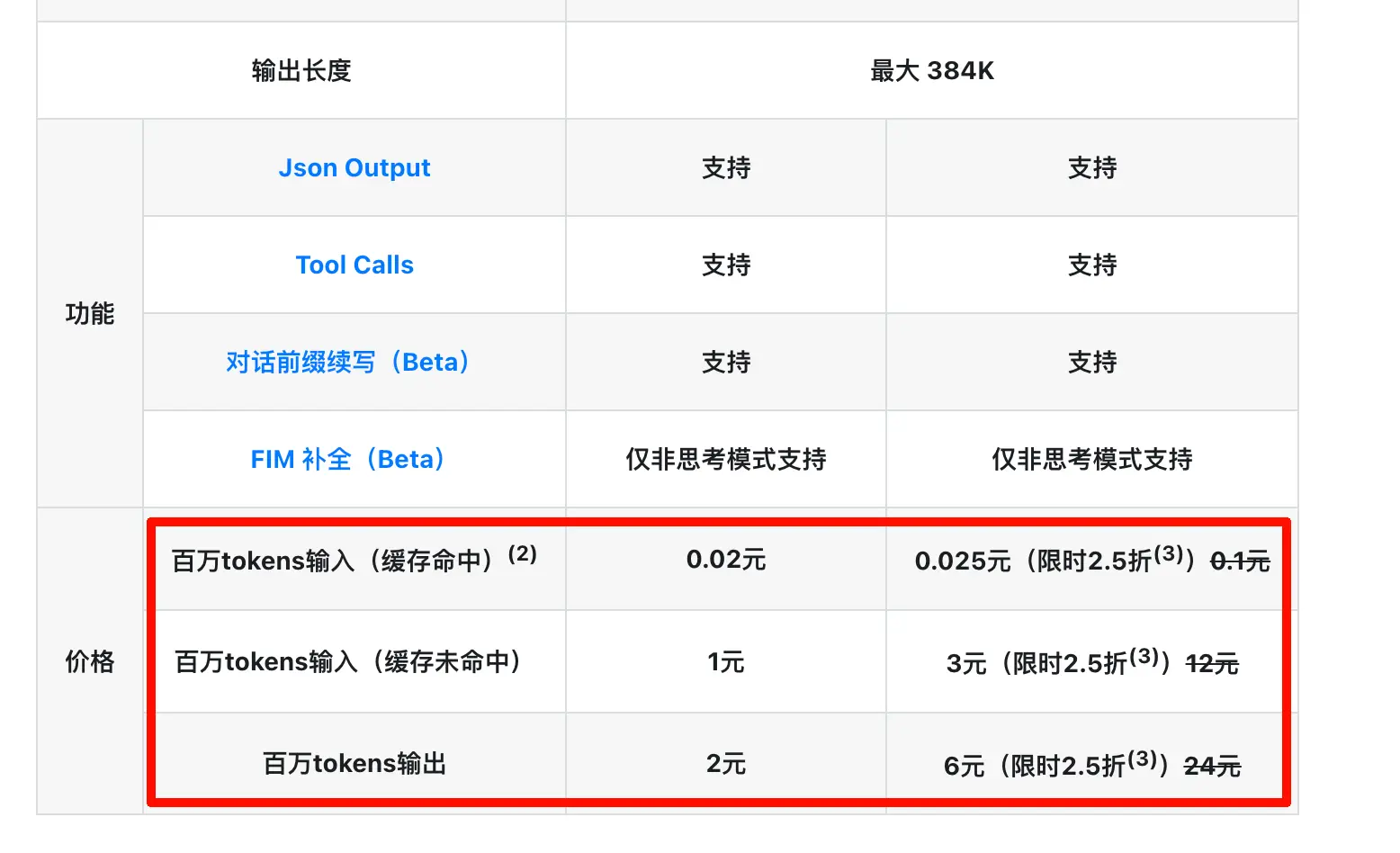
Ini dia DeepSeek yang kita kenal! Beberapa hari lalu saya mengkritik beberapa Coding Plans yang sulit didapat dan pengalamannya buruk. DeepSeek sepertinya langsung menurunkan harga API secara keseluruhan hingga di bawah harga Coding Plans. Terutama sekarang banyak Coding Plans yang melarang penggunaan di luar pemrograman, ketulusan DeepSeek semakin menonjol.
Beberapa API Coding Plans mungkin akan memblokir Anda jika mengintegrasikan terjemahan, tapi DeepSeek tidak peduli—gunakan sesuka Anda.
GPT-5.5 dan DeepSeek V4 bekerja dengan sangat baik. Saya sudah mulai mempertimbangkan untuk membatalkan langganan Claude bulan depan. Dan beberapa ahli di sekitar saya sudah mencobanya.

Tapi kembali ke topik, beberapa dari Anda mungkin bertanya-tanya: apa sebenarnya arti input, output, dan cache?
Mari kita perkenalkan dulu apa yang dimaksud dengan cache hit.
Ini analoginya: Anda pergi ke warung mie langganan dan memesan “mie tarik sapi dengan telur, tanpa daun ketumbar” untuk pertama kalinya. Pemiliknya harus mengiris daging sapi segar, menguleni adonan, merebus telur, dan menyiapkan bahan-bahan—seluruh proses memakan waktu. Sepuluh menit kemudian, teman Anda datang dan memesan hal yang persis sama. Pemilik melihat bahan-bahan masih panas di panci dan mie dari adonan yang sama, jadi dia langsung menyajikannya—itulah yang disebut “hit”.
Saat AI memproses input Anda, pada dasarnya ia harus “mengunyah” semua teks yang Anda kirim (termasuk prompt sistem, riwayat percakapan, dan pertanyaan Anda saat ini) dan mengubahnya menjadi status internal perantara untuk model. Langkah ini benar-benar membutuhkan komputasi yang intensif.
Jika AI menemukan bahwa konten yang Anda kirim kali ini memiliki segmen awal yang besar yang persis sama dengan yang sebelumnya, ia langsung menggunakan kembali status perantara dari sebelumnya tanpa harus mengunyahnya lagi—itulah cache hit.
Perhatikan tiga poin penting:
- Harus merupakan kecocokan awalan yang persis. Bahkan jika Anda menambahkan spasi ekstra atau mengubah tanda baca di awal, cache menjadi tidak valid, dan dimulai dari awal lagi.
- Memiliki batas waktu. Bervariasi tergantung penyedia. Misalnya, Anthropic default hanya 5 menit (kedaluwarsa saat Anda di kamar mandi). Jika Anda ingin opsi 1 jam, harus bayar ekstra (2x harga input dasar). Cache DeepSeek bertahan dari beberapa jam hingga beberapa hari.
- Percakapan yang sama secara alami cenderung hit. Karena setiap putaran tambahan dalam percakapan, input baru = semua riwayat sebelumnya + respons AI + pertanyaan baru Anda. Riwayat besar sebelumnya persis sama, sehingga secara alami terjadi hit.
Apakah cache hit atau tidak sangat mempengaruhi harga. Itulah mengapa saya merekomendasikan untuk mendiskusikan hanya konten yang terkait dalam percakapan yang sama—bukan hanya untuk memori konteks, tetapi juga karena mempengaruhi cache hit. Memulai percakapan baru berarti membayar dari awal, sedangkan melanjutkan percakapan berarti mendapatkan diskon.
Jadi, arti dari “per juta token input (cache hit)”, “per juta token input (cache miss)”, dan “per juta token output” adalah:
Per juta token input (cache miss): Bagian dari konten yang Anda kirim kali ini yang tidak dapat digunakan kembali oleh AI dari perhitungan sebelumnya dan harus dikunyah dari awal, dikenakan harga ini. Ini termasuk obrolan pertama kali, sesi baru, atau prompt yang diubah di awal.
Per juta token input (cache hit): Bagian dari konten yang Anda kirim kali ini di mana segmen awal kebetulan persis sama dengan instance sebelumnya dan langsung digunakan kembali oleh AI, dikenakan harga ini (jauh lebih murah). Dalam percakapan yang sama, riwayat dari putaran kedua, ketiga, dan seterusnya termasuk dalam kategori ini.
Per juta token output: Respons yang dihasilkan oleh AI dikenakan harga ini. Ini selalu yang paling mahal karena “generasi” mengkonsumsi lebih banyak daya komputasi daripada “pemahaman”—yang satu melibatkan AI berulang kali menyusun draf, memilih kata, dan membentuk kalimat di pikirannya, sementara yang lain melibatkan AI hanya meninjau materi.
Mari gunakan contoh konkret untuk merasakannya. Misalkan Anda menggunakan DeepSeek untuk memodifikasi kode sepanjang 3000 token:
- Pertanyaan pertama: Input 3000 token (semua miss) + output AI 500 token
- Kemudian tanya “Bisakah ini dioptimalkan lebih lanjut?”: Input menjadi lebih dari 3500 token (di mana 3500 adalah riwayat sebelumnya, semua cache hit; hanya beberapa lusin kata baru yang Anda tambahkan yang dihitung miss) + output AI 600 token
- Mulai percakapan baru, tempel kode lagi, dan tanya pertanyaan yang sama: 3000 token lagi semuanya miss
Jika harga miss 10 kali lipat harga hit, maka perbedaan biaya hanya untuk input antara “bertanya lanjutan dalam percakapan yang sama” dan “memulai percakapan baru untuk bertanya lagi” bisa hampir 10 kali lipat.
Jadi kali ini DeepSeek memangkas harga cache hit menjadi sepersepuluh dari harga semula, ditambah diskon 75% untuk model Pro. Untuk kasus penggunaan dengan konteks panjang + percakapan multi-putaran (seperti coding, analisis dokumen, obrolan panjang), ini hampir merupakan pemotongan harga yang menghancurkan. Jika Anda telah menulis Skills atau menyiapkan alur kerja otomatisasi, Anda tahu bahwa memanggil prompt panjang berulang kali adalah hal yang biasa. Penghematan nyata dari penurunan harga ini bahkan lebih dramatis daripada yang terlihat di atas kertas.
Terakhir, tips praktis: Biasakan menyelesaikan topik dalam percakapan yang sama sebelum memulai yang baru. Jangan selalu “hapus dan mulai baru”. Selain AI akan mengingat Anda, ini juga akan menghemat uang Anda.
Ringkasan
Apa yang kita pelajari hari ini:
- Apa itu cache hit — AI menyimpan input yang telah dikunyah sebelumnya. Jika awalannya sama kali ini, ia langsung menggunakannya kembali, menghemat daya komputasi, dan harga didiskon sesuai.
- Tiga kondisi utama — Harus kecocokan awalan yang persis, memiliki batas waktu (bervariasi dari menit hingga hari antar penyedia), dan percakapan yang sama secara alami cenderung hit.
- Apa arti ketiga harga tersebut — Cache miss = input yang dihitung ulang; cache hit = input yang digunakan kembali (termurah); output = respons yang dihasilkan AI (termahal).
- Mengapa output paling mahal — “Generasi” mengkonsumsi lebih banyak daya komputasi daripada “pemahaman”; AI berulang kali menyusun draf di pikirannya, dan harganya biasanya beberapa kali lipat dari input miss.
Poin penting yang perlu diingat:
- Melanjutkan dalam percakapan yang sama berarti diskon otomatis; sering memulai percakapan baru berarti membayar harga penuh setiap kali.
- Modifikasi prompt di bagian akhir; jika Anda mengubah bagian awal, cache menjadi tidak valid.
- Skenario konteks panjang + percakapan multi-putaran (coding, analisis dokumen, obrolan panjang) paling diuntungkan. Pemotongan harga DeepSeek pada dasarnya menghancurkan bagi pengguna seperti itu.