DeepSeekがついにV4モデルをリリースしました。ここ数日試してみましたが、とても素晴らしいです。特にFlashモデルはコストパフォーマンスに優れています。私が使っている経費管理ミニアプリの応答時間が元々5秒だったのが、今では2.5秒に短縮されました。一言で言えば、スムーズ!
唯一の欠点は、Proモデルがそれほど安くないことです。公式サイトによると、今年後半に国内のチップ供給が増えれば、さらに価格が下がるとのことです。
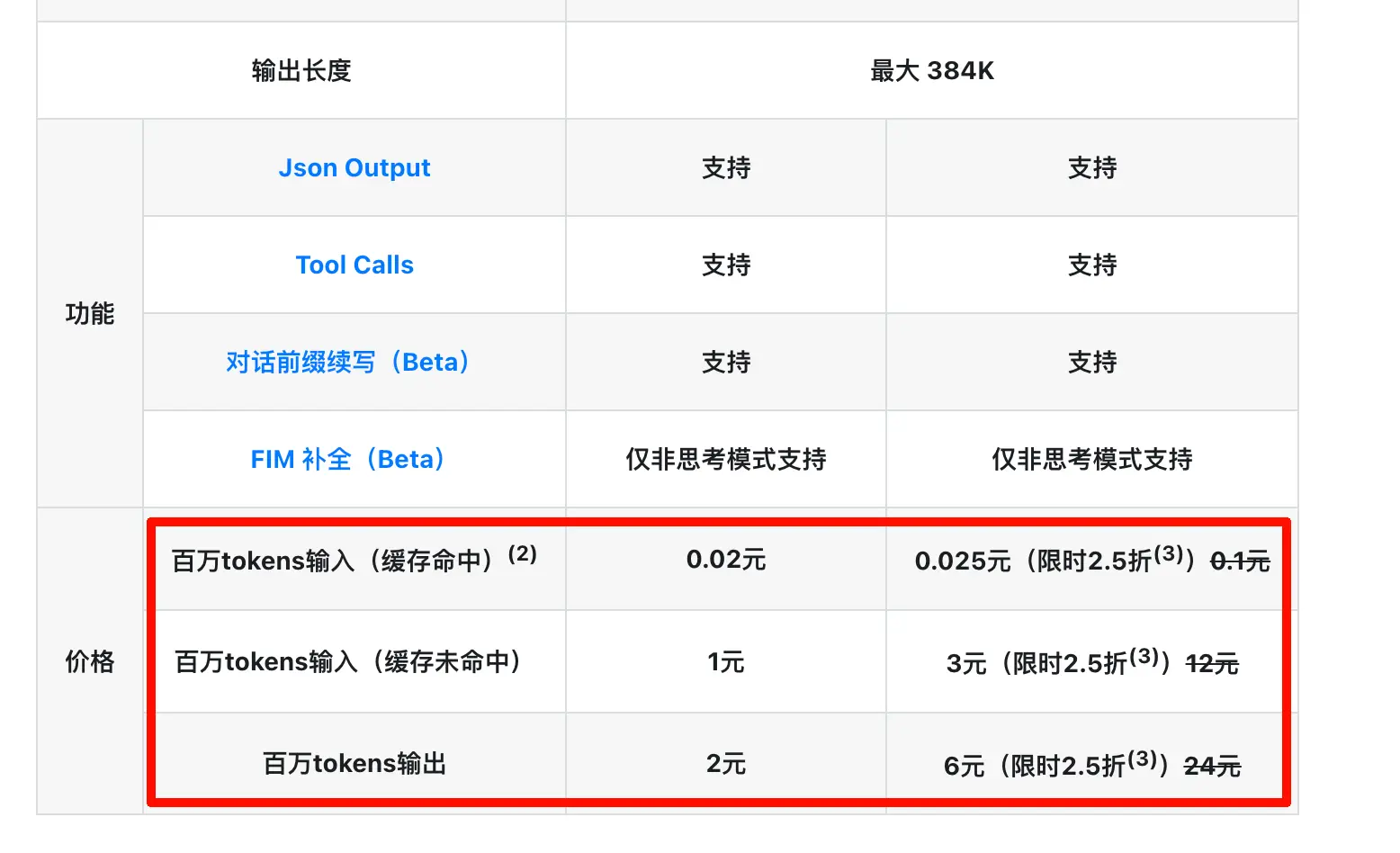
ところが、2日後にProモデルが期間限定で75%オフになりました(この割引は長期化するのではないかと疑っています)。昨日はさらにキャッシュヒット価格を元の10分の1に引き下げました!もう言うことはありません。立ち上がってペダルを踏み込むしかない!
これこそ我々の知るDeepSeekです!数日前、私は特定のCoding Plansが入手困難で体験が悪いと批判していました。DeepSeekはAPI全体の価格をCoding Plans以下に直接引き下げようとしているようです。特に今では多くのCoding Plansがプログラミング以外の使用を禁止しているため、DeepSeekの誠意が一層際立ちます。
一部のCoding PlansのAPIは、翻訳機能を統合すると利用禁止になるかもしれませんが、DeepSeekは気にしません。好きなように使ってください。
GPT-5.5とDeepSeek V4は素晴らしいパフォーマンスを発揮しています。来月のClaudeのサブスクリプションを解約しようかと考え始めています。周りの専門家の中にはすでに試した人もいます。

しかし本題に戻ると、皆さんの中には「入力」「出力」「キャッシュ」が実際に何を意味するのか疑問に思っている方もいるでしょう。
まず、キャッシュヒットとは何かを説明します。
例え話をしましょう。あなたがいつものラーメン屋に行き、初めて「牛肉引っ張り麺、卵入り、パクチー抜き」を注文します。店主は牛肉をスライスし、麺をこね、卵を茹で、材料を準備する必要があり、一連の工程に時間がかかります。10分後、友人が来てまったく同じものを注文します。店主は鍋の中の材料がまだ熱々で、麺も同じロットだと分かると、そのまま提供します。これが「ヒット」です。
AIがあなたの入力を処理するとき、基本的に送信されたすべてのテキスト(システムプロンプト、会話履歴、現在の質問を含む)を「噛み砕いて」、モデル用の内部中間状態に変換する必要があります。このステップは本当に計算負荷が高いのです。
AIが今回送信された内容の先頭の大きな部分が前回と完全に同じであることを検出すると、前回の中間状態を直接再利用し、再度噛み砕く必要がありません。これがキャッシュヒットです。
3つの重要なポイントに注意してください。
- 完全な前方一致でなければならない。先頭にスペースを1つ追加したり、句読点を変更しただけでもキャッシュは無効になり、最初からやり直しになります。
- 時間制限がある。プロバイダーによって異なります。例えばAnthropicのデフォルトはわずか5分(トイレに行っている間に期限切れ)。1時間オプションを希望する場合は追加料金(基本入力価格の2倍)が必要です。DeepSeekのキャッシュは数時間から数日間持続します。
- 同じ会話内では自然にヒットしやすい。会話が進むごとに、新しい入力=これまでの全履歴+AIの応答+新しい質問となるため、長い履歴部分が完全に同じになり、自然にヒットします。
キャッシュがヒットするかどうかは価格に大きく影響します。そのため、同じ会話内で関連する内容だけを議論することをお勧めします。文脈を記憶するためだけでなく、キャッシュヒットにも影響するからです。新しい会話を始めると最初から料金が発生しますが、会話を続けると割引が適用されます。
つまり、「100万トークンあたりの入力(キャッシュミス)」「100万トークンあたりの入力(キャッシュヒット)」「100万トークンあたりの出力」の意味は次の通りです。
100万トークンあたりの入力(キャッシュミス):今回送信した内容のうち、AIが以前の計算を再利用できず、最初から噛み砕かなければならない部分に適用される価格です。初回のチャット、新しいセッション、または先頭のプロンプトを変更した場合などが該当します。
100万トークンあたりの入力(キャッシュヒット):今回送信した内容のうち、先頭部分がたまたま以前のものと完全に一致し、AIが直接再利用した部分に適用される(はるかに安い)価格です。同じ会話内での2回目、3回目以降の履歴はこれに該当します。
100万トークンあたりの出力:AIが生成した応答に適用される価格です。これは常に最も高価です。なぜなら「生成」は「理解」よりも多くの計算能力を消費するからです。一方はAIが頭の中で繰り返し下書きし、単語を選び、文章を組み立てる作業であり、もう一方はAIが資料を確認するだけの作業です。
具体的な例で感覚をつかみましょう。DeepSeekを使って3000トークンのコードを修正するとします。
- 最初の質問:入力3000トークン(すべてミス)+AI出力500トークン
- 次に「これ以上最適化できますか?」と質問:入力は3500トークン以上になります(そのうち3500トークンは以前の履歴で、すべてキャッシュヒット;追加した数十の新しい単語だけがミスとしてカウント)+AI出力600トークン
- 新しい会話を開始し、同じコードを貼り付けて同じ質問をする:再び3000トークンすべてミス
ミス価格がヒット価格の10倍だとすると、「同じ会話内で続けて質問する」場合と「新しい会話を始めて再度質問する」場合の入力だけのコスト差は、ほぼ10倍になります。
今回DeepSeekはキャッシュヒット価格を元の10分の1に引き下げ、さらにProモデルの75%オフと組み合わせました。長いコンテキスト+複数ターンの会話(コーディング、文書分析、長いチャットなど)のユースケースでは、これはほとんど骨まで砕くような値下げです。スキルを作成したり、自動化ワークフローを設定したことがある方なら、長いプロンプトを繰り返し呼び出すのが当たり前だとご存知でしょう。この値下げによる実際の節約効果は、数字以上に劇的です。
最後に実用的なヒント:新しい会話を始める前に、同じ会話内でトピックを終わらせる習慣をつけましょう。いつも「クリアして新しく始める」のはやめましょう。AIがあなたを覚えているだけでなく、お金も節約できます。
まとめ
今日学んだこと:
- キャッシュヒットとは — AIが前回噛み砕いた入力を保存しておき、今回の先頭が同じであれば直接再利用することで計算力を節約し、価格も割引される。
- 3つの重要な条件 — 完全な前方一致であること、時間制限があること(プロバイダーによって数分から数日)、同じ会話内では自然にヒットしやすいこと。
- 3つの価格の意味 — キャッシュミス=再計算される入力、キャッシュヒット=再利用される入力(最も安い)、出力=AIが生成した応答(最も高い)。
- 出力が最も高価な理由 — 「生成」は「理解」よりも多くの計算能力を消費する。AIは頭の中で繰り返し下書きし、価格は通常、入力ミスの数倍になる。
重要なポイント:
- 同じ会話を続けると自動的に割引。頻繁に新しい会話を始めると毎回全額支払うことになる。
- プロンプトは末尾を変更する。先頭を変更するとキャッシュが無効になる。
- 長いコンテキスト+複数ターンの会話のシナリオ(コーディング、文書分析、長いチャット)が最も恩恵を受ける。DeepSeekの値下げは、そのようなユーザーにとっては骨まで砕くようなものだ。