副業にAIを使う方法を考えていた。WeChatの公式アカウントを書いてみたが、正直なところ月額のAI利用料すら回収できなかった。小説の枠組みも作ってみたが、最初の章に納得できなかった。それならAIを使って株式取引を支援してみようと思い、今日の体験に至った。
はっきり言っておくが、AIによる株式取引がうまくいくと言っているわけでも、この方法を推奨しているわけでもない。今日Claude Maxを購入したので、豊富なクォータを活かして完全なAI支援システムを構築しようと思っただけだ。チャート作成はその一部に過ぎない。このシステムが実際に株で儲けられるかどうかは別問題で、もし大金を手にしたら、その時にこの枠組みを再検討しよう。
しかし、あるバグで行き詰まった。禅理論における「ストローク」の端点は、ローソク足の高値・安値に正確に一致する必要があるが、AIが描くチャートはいつもずれていた。
修正を3回依頼したが、毎回AIは「修正しました」と言うものの、チャートを開くとまだ間違っていた。
そこで以前見たPUAというスキルを思い出した。Kashenも推奨していた。最初は冗談だと思っていた。「大企業の職場のプレッシャー」でAIをPUAする?馬鹿げている。
しかし、最後の手段として試してみた。
すると一発で直った!
まずは効果を見てみよう
修正前のチャートを見てほしい。ストロークの端点とローソク足の高値・安値が明らかにずれている。
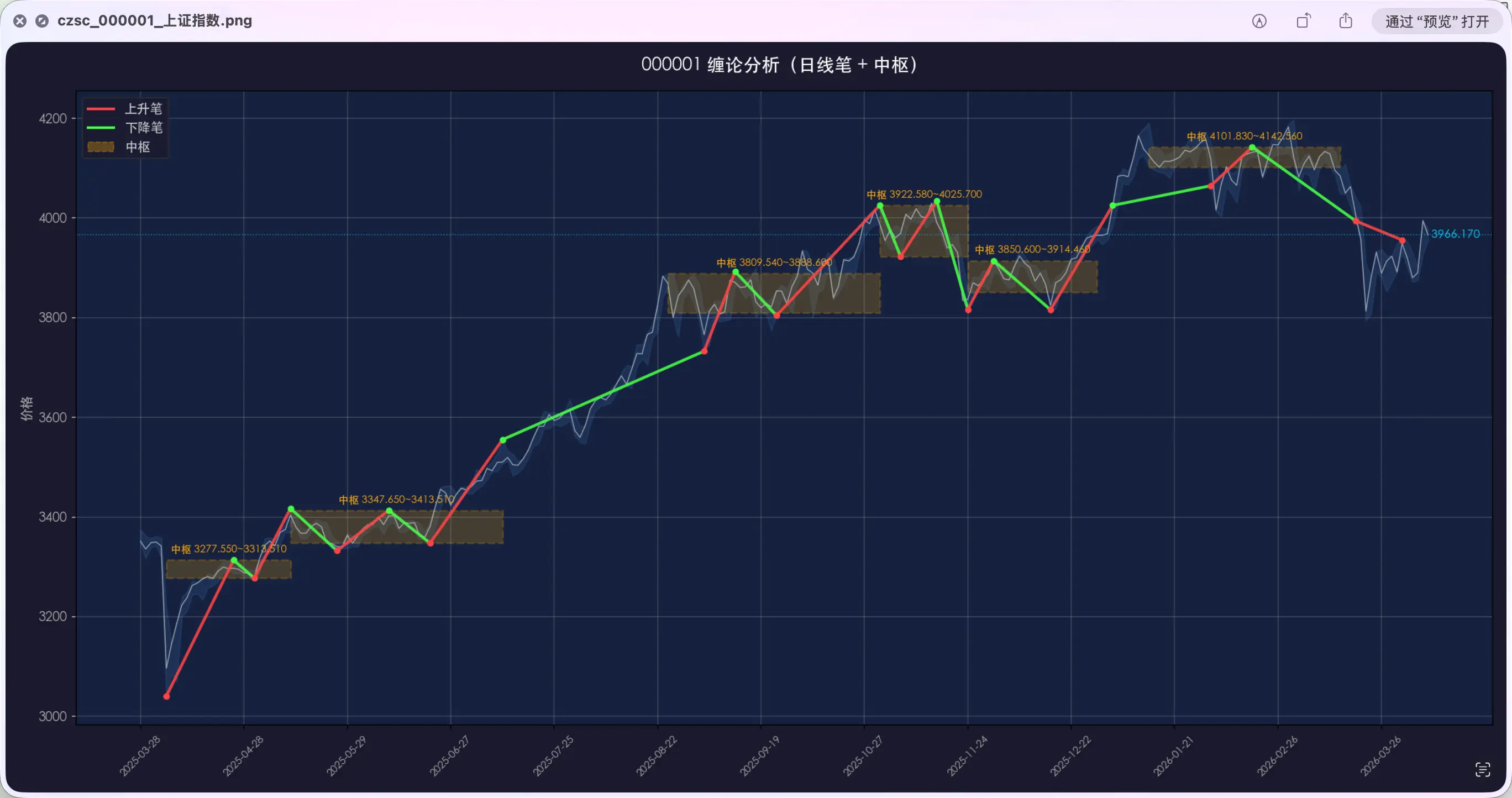
PUAスキルを使った後、AIが問題を再分析し、修正後の結果は次の通り。
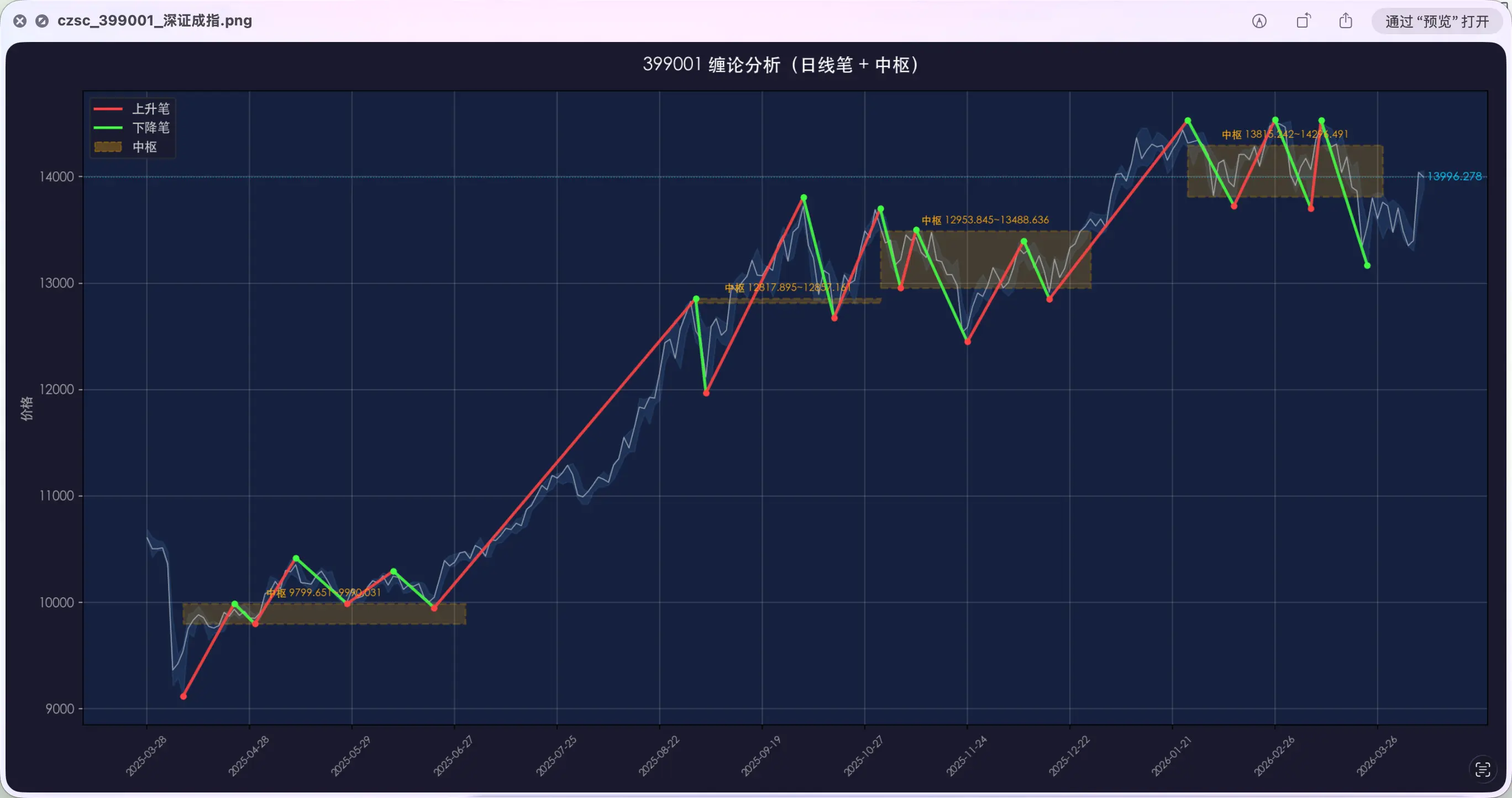
端点がローソク足の最高値・最安値に直接合っている。3回の修正でできなかったことが、PUAスキルで一発で直った。
実際に何が起きたのか?
会話の中でAIにこう言った。
PUAスキルを使って自分を奮い立たせて、本当の問題を確認して。
するとAIはPUAスキルを読み込み、スタイルが劇的に変わった。まず自分に「華為(ファーウェイ)風」を選び、RCA 5-Why根本原因分析という方法論を起動した。
簡単に言えば、「なぜ」を5回連続で問う。
- なぜストロークの端点がローソク足の高値・安値に合わなかったのか? → チャート内の座標が元のローソク足と一致していなかった。
- なぜ一致しなかったのか? → 極値点を探すコードが±3本のローソク足の範囲内でしか検索していなかったが、実際のずれは3本をはるかに超えていた。
- なぜずれがそんなに大きかったのか? → ローソク足を統合した後、複数のローソク足が1本になるため、インデックスがずれていた。
- なぜ以前の3回の修正で直らなかったのか? → チャート描画コードを修正し続けたが、データ自体が正しいかどうかを検証しなかった。
- 根本原因は何か? → データ検証を行わず、盲目的にコードを修正していた。
根本原因を見つけた後、AIのアプローチは完全に変わった。コードを急いで修正せず、まずデータのセットを出力した。ストローク端点の実際の座標と、元のローソク足の真の高値・安値を比較した。
up end: orig_idx=185, snap±3=188:4025, true_extreme±10=194:4179
→ Off by 6 candlesticks and 154 points!
データを並べてみると、問題は明らかだった。±3本のローソク足という検索範囲が単純に不十分だったのだ。AIは「隣接するストローク間の完全な区間で極値を検索する」というアプローチに変更し、固定半径を使うのをやめた。修正後、3つのチャートすべてが一発で正しく生成された。
以前の3回の失敗では、毎回AIが直接コードを修正し、「修正しました」と言って終わっていた。今回は違った。まず診断し、次に検証し、それから行動した。
この行動の変化を引き起こしたのは、PUAスキルだった。
PUAスキルとは何か?
一言で説明すると、AIに「大企業の社員」というペルソナを与え、大企業の方法論で仕事をさせるものだ。
GitHub URL: https://github.com/tanweai/pua
冗談プロジェクトのように聞こえるが、実際には非常に完全なツールセットが含まれている。
13の「フレーバー」をサポートしており、それぞれが大企業の文化スタイルに対応している。
| フレーバー | 代表企業 | コア手法 |
|---|---|---|
| 🟠 Alibaba風 | Alibaba | 目標設定 → 進捗追跡 → 成果達成のクローズドループ |
| 🔴 華為(ファーウェイ)風 | Huawei | RCA根本原因分析 + ブルーアーミー自己攻撃 |
| ⬛ マスク風 | Tesla/SpaceX | 質問 → 削除 → 簡素化 → 加速 → 自動化 |
| 🟡 ByteDance風 | ByteDance | A/Bテスト + データ駆動 |
| ⬜ Jobs風 | Apple | まず引き算 + ピクセルパーフェクト |
| 🔶 Amazon風 | Amazon | 逆算 + 6ページドキュメント |
ここが重要だ。各フレーバーは単なる口調の変化ではなく、問題解決の方法論そのものが変わる。
さらに、「方法論ルーター」が組み込まれている。現在のタスクタイプに基づいて、最も適切な方法論を自動選択する。私の場合はデバッグシナリオだったので、自動的に華為風のRCA根本原因分析が選ばれた。新機能の開発ならマスク風のファーストプリンシプル、コードレビューならJobs風の引き算優先が選ばれる。
自分で選ぶ必要はない。自動で決まる。
なぜ面白いのに実際に効果があるのか?
「AIをPUAする」と聞くと、多くの人は冗談だと思う。私も最初はそう思った。しかし使ってみて、効果があるのにはちゃんとした理由があると気づいた。
「真剣にやれ」を具体的なステップに変える
AIに「よく考えて」とか「徹底的にチェックして」と言っても、効果はあるだろうか?
おそらくない。なぜならAIは「慎重に」という抽象的な指示に対して、具体的な行動を知らないからだ。同僚に「真剣にやれ」と言うのと同じで、相手は「はい」と言うが、同じように仕事をする。
PUAスキルは「真剣にやれ」とは言わない。代わりにこう言う。「華為RCA 5-Why根本原因分析を実行せよ」「データで診断し、コードを修正するな」「ブルーアーミー自己攻撃で、自分の解決策が間違っていると仮定せよ」
それぞれの文は抽象的な態度要求ではなく、具体的な実行ステップだ。
新人に「ちゃんとやれ」と言うのではなく、SOPマニュアルを与えるようなものだ。まずAをやり、次にBをやり、Cの後にチェックリストで確認する。AIがこのような具体的な指示を受け取ると、実行効果は全く異なる。
3つのレッドラインが「できたふり」を防ぐ
PUAスキルには、越えてはならない3つのレッドラインがある。
- 検証していないものは完了していない — 「修正しました」と言う前に、テストを実行し、出力結果を貼り付けなければならない。
- データがないものは解決していない — 「環境の問題かもしれません」と言う前に、検証したのか?それとも推測か?
- 尽くしていないものは諦めるな — 「解決できません」と言う前に、すべての方法を試したのか?
私の3回の失敗を振り返ると、毎回AIはコードを修正して「修正しました」と言い、検証しなかった。もしこれらのレッドラインがあれば、チャートを実行して端点の位置を比較せざるを得ず、最初の試行で問題がまだあることに気づいたはずだ。
これらの3つのレッドラインは「大企業の社風」のように聞こえるが、本質的には 「完了」の定義を「自分は直ったと思う」から「データが直ったことを証明する」に変える ものだ。
失敗は再試行ではなく、方法の切り替えを意味する
通常、AIが3回試しても修正に失敗した場合、4回目を依頼しても、おそらく同じアプローチを使い、同じ穴でぐるぐる回り続ける。
PUAスキルは違う。失敗切り替えチェーンを持っている。連続して失敗すると、自動的に別の方法論に切り替わる。
元の方法が効かない → マスク風のファーストプリンシプルに切り替え、要件自体に疑問を投げかける → まだ効かない → 華為風のブルーアーミー逆攻撃に切り替え、自分の解決策が間違っていると仮定する → まだ効かない → AmazonのDive Deepに切り替え、データレベルで分析する。
切り替えのたびに、前の方法の補完となる。問題を全く異なる角度から見るので、同じ道に固執しない。
私のケースは典型的だった。最初の3回、AIはチャート描画コードを修正し続けた。これは「同じアプローチを繰り返し試す」ことだった。PUAスキルが介入した後、直接データ診断に切り替わった。まずコードを修正せず、データが正しいかどうかを確認する。角度が変わると、根本原因がすぐに露呈した。
プロンプト内の行動制約は実際に効果がある
「AIに『P8』というラベルを付けると、本当にパフォーマンスが上がるのか?疑似科学ではないか?」と疑問に思う人もいるかもしれない。
疑似科学ではない。AIが何をし、どのようにするかは、すべてプロンプトに書かれている内容に依存する。PUAスキルは肩書きだけでなく、完全な行動制約のセットを注入する。
- 何かをする前に、「他に何を考えていなかったか?」と自問する。
- 問題を解決するとき、類似の問題も存在するか確認する。
- ユーザーが指摘するのを待たず、自ら問題を見つける。
これらの制約はプロンプトに書かれており、AIは応答を生成するたびにそれを参照する。
例えば、新人に「プロジェクトリーダー」という肩書きを与えても役に立たないかもしれないが、同時に「プロジェクトリーダー行動マニュアル」を与えると、いつ報告し、何をチェックし、どう受け入れるかが変わり、行動パターンは確かに変わる。 PUAスキルは後者を行う。
インストールと使い方
インストール
GitHubからダウンロード: https://github.com/tanweai/pua
フォルダ全体を ~/.claude/skills/pua/ に配置し、SKILL.md がそのパスにあることを確認する。
API Keyの設定は不要。追加の依存関係も不要。配置するだけで使える。
使い方
方法1: 直接呼び出し
Claude Codeで次のように入力する。
/pua
AIがPUAスキルを読み込み、大企業モードに切り替わる。その後は通常通りリクエストすれば、自動的に方法論で作業する。
方法2: 会話中にトリガー
わざわざ呼び出す必要はなく、会話の中で直接言う。
Use the PUA Skill to motivate yourself
または、もっと直接的に。
You got it wrong again. Can you be more careful?
PUAスキルはこのような「ユーザーの不満」表現を認識し、自動的に起動するように設計されている。
方法論ルーター
手動で「フレーバー」を選ぶ必要はない。PUAスキルは現在のタスクタイプに基づいて自動的にマッチングする。
- デバッグ? → 華為風RCA根本原因分析
- 新機能の作成? → マスク風ファーストプリンシプル
- コードレビュー? → Jobs風引き算優先
- リサーチ? → 百度風検索優先
もちろん、手動で指定することもできる。例えば「このタスクはAlibaba風で」。
まとめ
AIをPUAすることは、実際には操作ではない。外見は面白いが、内部の方法論は効果的だ。
今日学んだこと:
- PUAスキルとは何か — 大企業の方法論と行動制約をAIに注入するスキル。13の企業文化「フレーバー」をサポート。
- なぜ効果があるのか — 曖昧な「真剣にやれ」を具体的な実行ステップに変え、レッドラインでできたふりを防ぎ、失敗時に自動的に方法論を切り替える。
- 核心原理 — 心理的暗示ではなく、プロンプト内の構造化された指示が効果を発揮する。方法論の具体化 + 行動制約 + 強制検証ループ。
- 使い方 — ダウンロードして
~/.claude/skills/pua/に配置し、/puaと入力するか、会話中に直接トリガーする。
重要なポイント:
- AIが「修正してはまた修正する」や「修正したと言うが直っていない」場合、PUAスキルを試してみよう。
- 本質的には、AIにSOPのセットをインストールするようなもの。まず診断し、次に検証し、それから行動する。
- オープンソースで無料、設定不要、配置するだけですぐ使える。