从打字员到超级助手
之前我们学会了用Claude Code做项目,你可能已经体验到了AI编程的强大。但你有没有发现一个问题:
每次做类似的事情,都要重新描述一遍需求。
比如你想让AI帮你:
- 写Git提交信息
- 审查代码
- 生成项目文档
- 同步文件
这些任务你可能每天都要做好几次,但每次都要打一长段话告诉AI该怎么做,太累了!
这就像你每次点外卖,都要跟店家说:
“我要一份红烧牛肉面,不要香菜,多加辣椒,面要硬一点,汤要少一点……”
有没有办法把这些常用操作变成一键调用?
有的,这就是今天要讲的Skill。
什么是Skill?
一句话解释
Skill = AI的快捷指令
就像你手机上的快捷指令App,Skill把复杂的操作封装成一个简单的命令。
官方定义
Skill指的是可复用的"能力模块",把工具/API/脚本与提示封装成标准接口,让AI按需调用完成特定任务。
它强调:
- 清晰的输入输出
- 依赖与版本管理
- 可测试、可更新
- 把通用AI变成面向业务的专业助手
通俗理解
没有Skill的时候:
你:请帮我审查这段代码,检查以下几点:
1. 是否有性能问题
2. 是否有安全漏洞
3. 代码风格是否符合规范
4. 是否有重复代码
5. 变量命名是否清晰
6. 注释是否完整
……(还要继续描述10行)
有了Skill之后:
你:/review
AI自动按照预设的标准审查代码,并给出详细报告。
差别看出来了吗? 从几百字变成一个命令,这就是Skill的威力。
Skill、提示词、MCP的区别
很多人会问:Skill、提示词(Prompt)、MCP这三个概念有什么区别?
概念对比
| 对比项 | 提示词(Prompt) | Skill | MCP |
|---|---|---|---|
| 本质 | 文本指令 | 封装好的能力模块 | 连接外部工具的协议 |
| 复用性 | 低,每次要重新输入 | 高,定义一次重复使用 | 高,一次配置持续使用 |
| 复杂度 | 简单 | 中等 | 复杂 |
| 能力范围 | 仅文本处理 | 文本 + 简单脚本 | 文本 + 外部系统交互 |
| 学习门槛 | 最低 | 中等 | 较高 |
用比喻说明
提示词 = 口头指令
- 你每次都要口头告诉AI做什么
- 适合一次性、临时的任务
- 例如:“帮我翻译这段话”
Skill = 工作流程
- 把常用的指令固化成标准流程
- 适合重复性、标准化的任务
- 例如:"/commit"自动生成Git提交信息
MCP = 外部系统
- 让AI连接到外部工具和数据源
- 适合需要访问外部系统的任务
- 例如:连接Obsidian读写笔记、连接数据库查询数据
三者的关系
提示词 → 最基础的交互方式
↓
Skill → 封装了提示词 + 简单逻辑
↓
MCP → Skill + 外部系统的能力
形象地说:
- 提示词 = 你自己做饭
- Skill = 用微波炉加热速食
- MCP = 连接外卖平台点餐
什么时候用哪个?
用提示词,如果:
- 任务简单、一次性
- 需求灵活多变
- 不需要复用
用Skill,如果:
- 任务重复性高
- 有标准化流程
- 想提高效率
用MCP,如果:
- 需要访问外部数据(数据库、API、文件系统等)
- 需要和其他软件交互(Obsidian、浏览器等)
- 需要实时获取信息
实际案例对比:
场景一:翻译一段话
- 用提示词:“请翻译这段话”(最简单)
场景二:每天翻译很多文档
- 用Skill:"/translate"(标准化翻译流程)
场景三:自动翻译Obsidian笔记并保存
- 用MCP:连接Obsidian,自动读取、翻译、保存(最强大)
Skill的基本使用
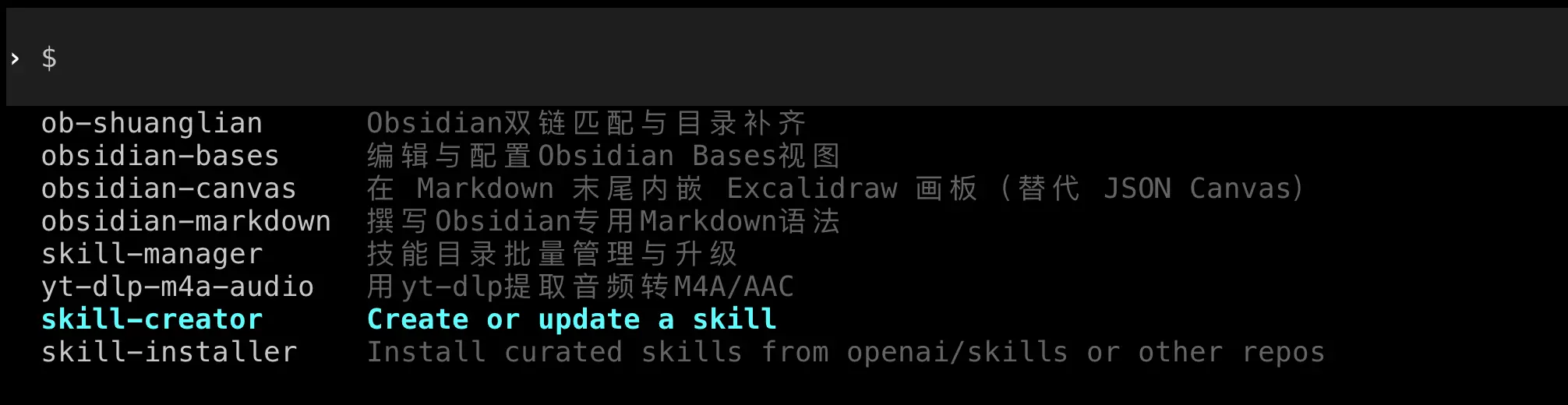
怎么查看已有的Skill?
在Claude Code或Codex中,输入:
/skill
会列出所有可用的Skill。

怎么使用Skill?
方法一:直接执行
输入 /skill,然后用Tab键选中想用的Skill,按回车执行。

方法二:带参数执行
选中Skill后,继续输入你的具体需求:
/translate 把这段代码的注释翻译成英文
常用的内置Skill
大部分AI编程工具都自带一些常用Skill:
| Skill | 作用 | 示例 |
|---|---|---|
/commit |
自动生成Git提交信息 | /commit |
/review |
审查代码质量 | /review |
/fix |
修复代码错误 | /fix |
/test |
生成测试用例 | /test |
/doc |
生成文档 | /doc |
/refactor |
重构代码 | /refactor |
这些内置Skill已经能解决80%的日常需求。
创建自己的Skill
如果内置Skill不够用,你可以创建自己的Skill。
两种创建方法
方法一:让AI帮你创建(推荐)
在Codex中自带了一个创建Skill的Skill(很绕,但很强大)。
操作步骤:
- 输入
/skill - 找到"Create Skill"相关的选项
- 选中后,告诉AI你想要什么Skill
示例:
/create-skill
我想要一个翻译Skill,功能是:
1. 自动检测代码中的中文注释
2. 翻译成英文
3. 保持代码格式不变
AI会自动帮你创建Skill文件,并放到正确的位置。
方法二:手动创建
如果你想更深入了解Skill的结构,可以手动创建。
Skill的文件结构:
每个Skill是一个文件夹,里面必须包含 SKILL.md 文件:
my-skill/
├── SKILL.md # Skill的说明和配置
└── scripts/ # 可选:辅助脚本
└── helper.py
SKILL.md的基本格式:
|
|
后面我们会详细介绍如何创建一个完整的Skill。
安装别人的Skill
GitHub上有很多现成的Skill,你可以直接下载使用。
找到Skill文件夹
Codex的Skill位置:
- Mac/Linux:
~/.codex/skills/ - Windows:
%USERPROFILE%\.codex\skills\
Claude Code的Skill位置:
- Mac/Linux:
~/.claude/skills/ - Windows:
%USERPROFILE%\.claude\skills\
安装步骤
- 打开Skill文件夹
如果文件夹不存在,可以手动创建:
|
|

- 下载Skill文件
从GitHub或其他来源下载Skill文件夹。
- 复制到Skill目录
把整个Skill文件夹复制到对应的skills目录。
- 重启工具
注意: Codex目前不支持热更新,需要退出重启才能看到新Skill。Claude Code通常可以自动识别。
验证安装
重启后,输入 /skill 查看列表,确认新Skill已经出现。
实战案例——创建一个同步Skill
问题场景
如果你同时使用Codex和Claude Code(很多人都这样),会遇到一个麻烦:
两个工具的Skill要分别管理,非常不方便。
- Codex的Skill在
~/.codex/skills/ - Claude Code的Skill在
~/.claude/skills/
每次你在Codex创建了一个好用的Skill,还要手动复制到Claude的文件夹,太繁琐了!
这时候我们就可以创建一个Skill,自动同步两个文件夹的内容,用skill来管理skill
这个Skill会:
- 检查两边的Skill差异
- 报告哪些Skill需要同步
- 经过你确认后,自动同步
我们只需要把需求告诉AI即可
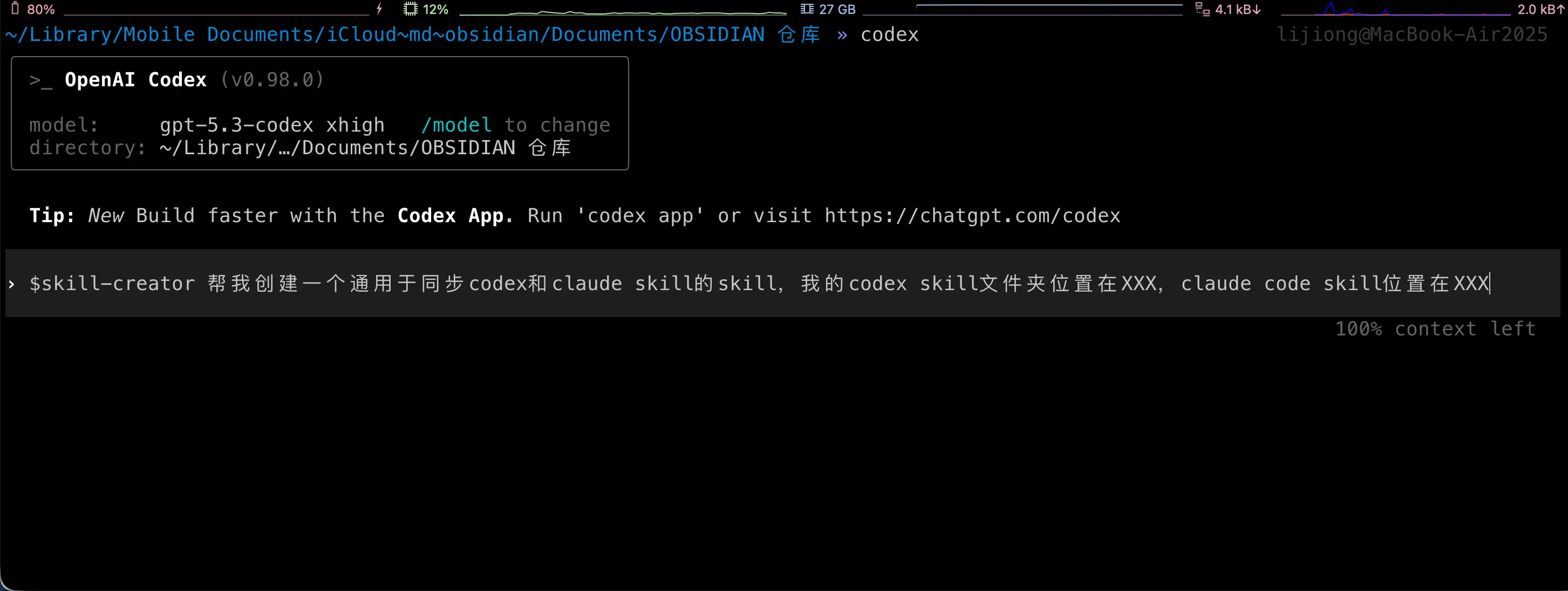
下面是AI帮你做的事情,请注意,这些步骤都是它自动的,不用你任何操作! 放在这里只是演示
第一步:创建Skill文件夹
在Codex或Claude Code的skills目录下,创建一个新文件夹:
|
|
第二步:创建SKILL.md
在文件夹中创建 SKILL.md 文件:
|
|
重要: 把上面的路径改成你自己的实际路径!
第三步:创建脚本文件
在Skill文件夹下创建 scripts 目录,然后创建 sync_skills.py:
|
|

sync_skills.py 的完整代码:
|
|
重要: 记得修改开头的路径:
|
|
改成你实际的路径。
使用同步Skill
第一步:查看差异
在Claude Code或Codex中输入:
/codex-claude-skill-sync
AI会自动运行脚本,报告两边的Skill差异。
第二步:确认同步
如果你同意同步,告诉AI:
同意,请执行同步
AI会运行 python3 scripts/sync_skills.py --apply 完成同步。
搞定! 以后你在任意一边创建或修改Skill,只需要运行一次这个同步Skill,两边就会保持一致。
Skill进阶技巧
技巧一:组合使用Skill
多个Skill可以串联使用:
/review 然后 /fix 修复发现的问题
AI会先审查代码,然后根据审查结果自动修复。
技巧二:自定义Skill参数
很多Skill支持参数:
/commit --type feat --scope api
会生成符合特定格式的提交信息。
技巧三:Skill模板
你可以创建Skill模板,快速生成新Skill:
- 复制一个现有Skill文件夹
- 修改SKILL.md
- 保存即可
技巧四:团队共享Skill
把Skill文件夹放到Git仓库,团队成员可以共享:
|
|
总结
今天学到了什么:
- Skill是什么:可复用的能力模块,把复杂操作变成简单命令
- Skill vs 提示词 vs MCP:三者的区别和适用场景
- 如何使用Skill:
/skill查看和调用 - 如何创建Skill:让AI帮忙或手动创建
- 如何安装Skill:复制到对应文件夹
- 实战案例:创建同步Skill,解决多工具管理问题
核心要点:
- Skill让AI从"打字员"升级为"专业助手"
- 常用操作应该封装成Skill
- 好的Skill可以节省90%的时间
下期预告
下一篇我们会介绍MCP:
MCP深度解析——让AI连接整个世界
MCP(Model Context Protocol)是AI工具的"插件系统",可以让Claude Code或Codex:
- 连接Obsidian,自动整理笔记
- 连接浏览器,自动操作网页
- 连接数据库,智能查询数据
- 连接任何你想连接的工具
这才是AI编程的最终形态!
敬请期待!
如果觉得有帮助,记得关注这个系列!