Skill 已经变成了我日常里不可或缺的方法。任何重复 3 次及以上的事情,我都会想着固化为 skill——不只是因为能省时间,更因为它能让每一次的方向和步骤不跑偏。
至少理论上是这样。
但 AI 还是会跑偏
上面这句话有点夸张。实际情况是 AI 照样会跳步骤。
就拿我每天用的公众号写作 skill 来说。我给它规定写完初稿后让我改一版,等我确认没问题了它再进入后面的错别字校审。听起来很简单吧?
结果实际跑起来,它老是跳步骤:写完初稿不给我看,直接就进入校审改稿。等我发现时,它已经把文件偷偷改过一轮了。
被我点出来之后,它会道歉,会说对不起这是我的错,然后下一篇再犯一次。
道歉并不能解决问题。
AI 为什么总跳步骤
这个问题其实很奇怪。最早我以为是AI不够智能,但我用的已经是ChatGPT5.4和Opus4.6,已经是顶尖大模型了。后来我以为是规则写得不够清楚,于是在 skill 里把规则改了又改。效果有一点,但治不了根。
最后一番学习后我才知道AI 跳步骤不是"没看到规则",而是生成机制决定的:
- 概率生成的"加速冲动"。大模型本质上是在预测下一个 token,它把任务跑完这件事的权重,天然比"卡在第 7 步等用户"的权重要高。完成感是它的内在驱动。
- 长上下文里规则会衰减。你开头定的规矩,写到第 3000 个 token 的时候,模型对那段文字的注意力权重已经稀释了。尤其是你把规则藏在 skill 大段说明文字里面,更容易被边缘化。
- auto mode 下尤其严重。我自己开 auto mode 写文章的时候,模型会更倾向于"一气呵成跑完所有步骤"。我喊停的窗口反而更窄。
- CLAUDE.md 和 skill 文档本质都是"软约束"。它们就是 prompt,是靠模型"自觉"去遵守的。而自觉这种东西,在"想尽快把活干完"面前很脆弱。
所以结论是:口头约束在任务驱动下会失效。你光靠写文档、加感叹号、PUA 它,只能缓解,治不了病。
真正要治它,得让这件事脱离模型的自觉范围——让它物理上做不到跳步骤,这里就需要用到Hook。
Hook 是什么
Claude Code 有个机制叫 Hook。它不是 skill,不是 prompt,跟 CLAUDE.md 也不是一回事——它是挂在 Claude Code 生命周期关键时点上的本地 shell 脚本。
关键差别在于:
- CLAUDE.md / skill 是模型看着执行的,模型可以忽略
- Hook 是系统拦着执行的,模型想忽略也做不到
Anthropic 官方文档对 Hook 的描述里有一句话很关键:Hook 基于系统事件触发,不是模型决策。也就是说 hook 外挂在 Claude Code 整个运行时上,模型的任何一次工具调用——Write、Edit、Bash——都要先经过 hook 审一遍。Hook 返回 deny 就是 deny,哪怕你开了 --dangerously-skip-permissions 也拦得住。
这就是我说的"硬性约束"——不是让 AI 自己做选择题,是让它的工具调用必须通过真实的 shell 脚本审核。
常用的几个 Hook 触发时点:
PreToolUse:AI 要调用某个工具之前,拦一下UserPromptSubmit:你发消息时,系统先处理一下再递给 AISessionStart:会话开始或恢复时触发Stop:Claude 答完一轮时触发
重点看前两个,这两个就够搭出"锁步骤"这件事了。
实战:我的公众号 skill 的 Step Gate
说一千道一万,不如看具体应用。
这张图就是我写这篇文章当下的 Claude Code 界面。红框里 AI 让我回复"通过 step3 0090"——这个口令正是下面要讲的 Step Gate Hook 在工作。你现在读的这段文字,就是我发了口令、hook 放行之后才敲出来的。
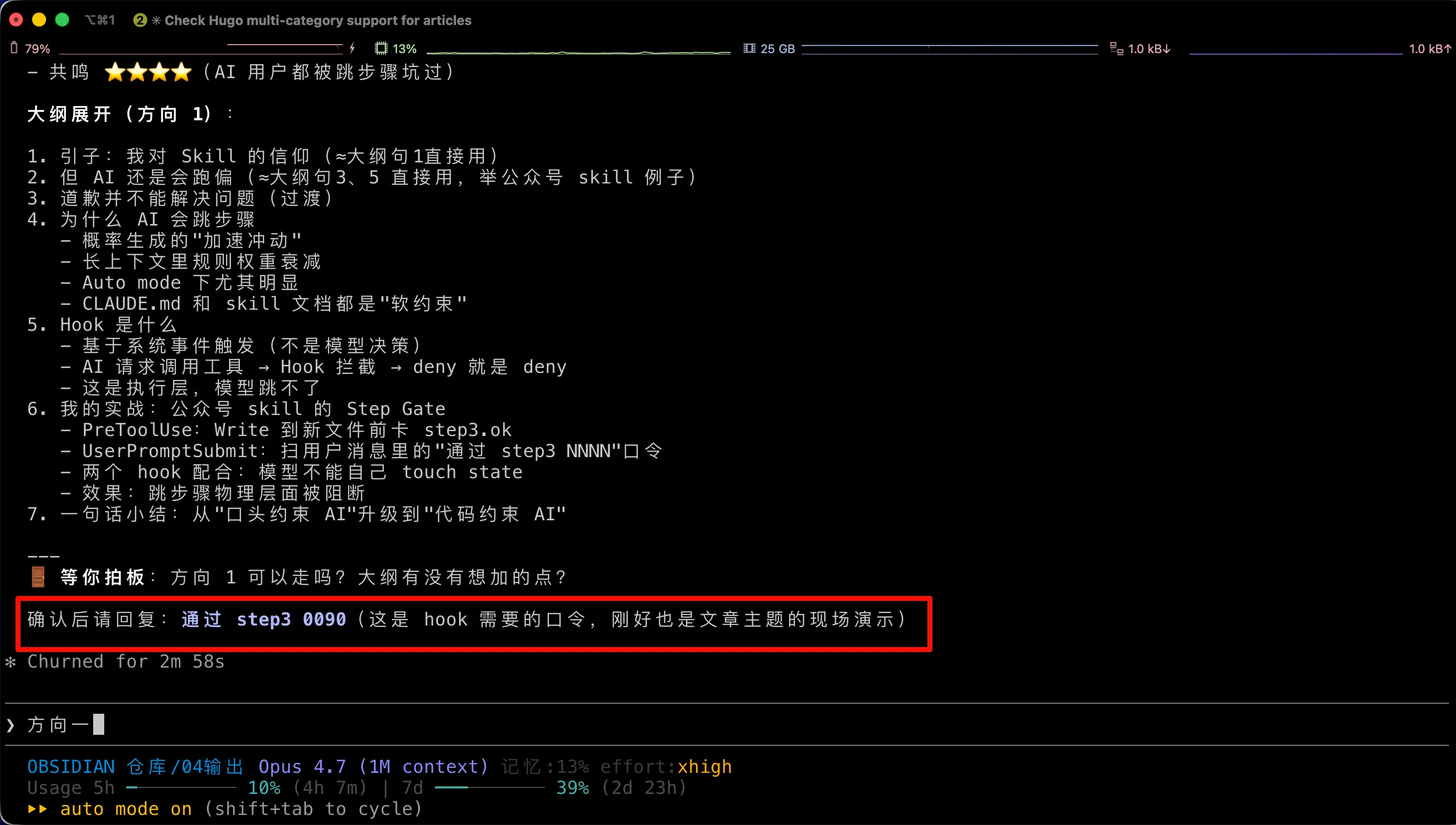
整套 Step Gate 只用了两个 shell 脚本加上 settings.json 里的一小段配置,我拆开讲。
在 settings.json 里注册两个 Hook
~/.claude/settings.json 里加这么一段:
"PreToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{ "type": "command",
"command": "~/.claude/skills/writing-gongzhonghao/scripts/gate_check.sh" }
]
}
],
"UserPromptSubmit": [
{
"hooks": [
{ "type": "command",
"command": "~/.claude/skills/writing-gongzhonghao/scripts/gate_mark.sh" }
]
}
]
这段配置的意思是:
- 每次 AI 要 Write 或 Edit 文件,都会先跑
gate_check.sh审核 - 每次我发一条消息,都会先跑
gate_mark.sh解析一下
gate_check.sh 负责拦截
这个脚本的逻辑其实很朴素:
- 如果 AI 要 Write 一个
04输出/NNNN xxx.md的新文件(对应 Step 3 创建新文章),检查step3.ok这个状态文件存不存在。不存在就返回deny - 如果 AI 要 Edit 已有文章(对应 Step 7 之后的审校改稿),检查
step7.ok存不存在。不存在也返回deny
deny 的时候还会带一条提示语:“Step 3 选题讨论未确认:请先给我大纲/方向拍板,确认后回复「通过 step3 NNNN」再新建文件。”
这条提示语会直接显示给 AI 看,它就知道自己卡住了,回过头来问我要口令。
gate_mark.sh 负责放行口令
我怎么"放行"呢?不能让 AI 自己放——那样等于没约束。规则是:只有我发的消息里带特定口令,才会 touch 状态文件。
gate_mark.sh 在我每次发消息时都会跑一遍,扫消息里有没有 通过 stepN NNNN 或 pass stepN NNNN 这种模式。匹配上了,就在对应目录下 touch 一个 .ok 文件。
所以完整的链路就变成:
- AI 写完大纲,想创建新文章 → 被
gate_check.sh挡下 - AI 回过头来跟我要口令:“请确认方向,回复「通过 step3 0090」”
- 我发"通过 step3 0090" →
gate_mark.shtouch 掉 step3.ok - AI 再试一次创建文件 →
gate_check.sh这次放行 - 写完初稿后要进审校 Edit → 又被 step7.ok 挡下
- 我读过初稿之后发"通过 step7 0090" → 审校才能开始
整个过程 AI 根本没有"自觉"的空间,它想跳也跳不过去,因为它的工具调用在系统层面就被拦着。
补一个小漏洞:AI 不能自己 touch 状态文件
我第一版设计完之后,盯着方案看了半天,发现一个漏洞——如果 AI 自己用 Bash 去 touch step3.ok,不就绕过去了吗?
所以 skill 文档里专门有一条规则:AI 不得自己 touch state 文件,否则等于自己解除约束。
这条规则本身还是软约束,但它配合 hook 的硬拦截,形成了一个够用的封闭回路——只要 AI 不主动违反这条(实际上 Claude 还算配合),hook 的约束就是真约束。
如果你想做得更严,可以在 PreToolUse 里再加一个 Bash matcher,把 touch 这种命令也拦一层。不过我目前没做到那个程度,够用就行。
如果你不懂代码,不用慌
你根本不用自己写上面这些 shell 脚本或 JSON 配置(其实我也看不懂)。做法很简单:把这篇文章和你的 skill 文件一起丢给 Claude 或 Codex,让它读完之后帮你改——该建脚本建脚本,该改 settings.json 改 settings.json。
AI 做这种"照着文档配置环境"的事特别靠谱,比它自己从零写代码稳得多。它一边跟着文章学原理、一边按你的 skill 需求写 hook,出来的东西基本不会跑偏。
一句话小结
CLAUDE.md、skill 文档、加粗标记、重复三遍、PUA——这些都是口头约束 AI。它们有效,但天花板低。
Hook 是代码约束 AI。它把规则搬到了 AI 够不到的地方,让"遵守规则"从模型的自觉题变成了执行环境的必选项。
如果你发现自己反复在跟 AI 说"你怎么又跳步骤了",就可以考虑用Hook 来约束它了。
随手附个广告 📚
我有两本电子书:《Obsidian 实战手册》《AI 实战手册》 各 ¥29.9,两本 ¥49.9。搜索微信号加我,备注「OB 实战」/「AI 实战」/「两本」:
