DeepSeek终于发布了V4模型,我这几天体验下来感觉十分不错,尤其是Flash性价比优越。我自己的记账小程序原来反应时间是5秒,现在已经降到了2.5秒。一个字就是丝滑!
美中不足的是Pro的价格不是很便宜,看官网的意思等下半年国内芯片供应上来之后价格还会下降。
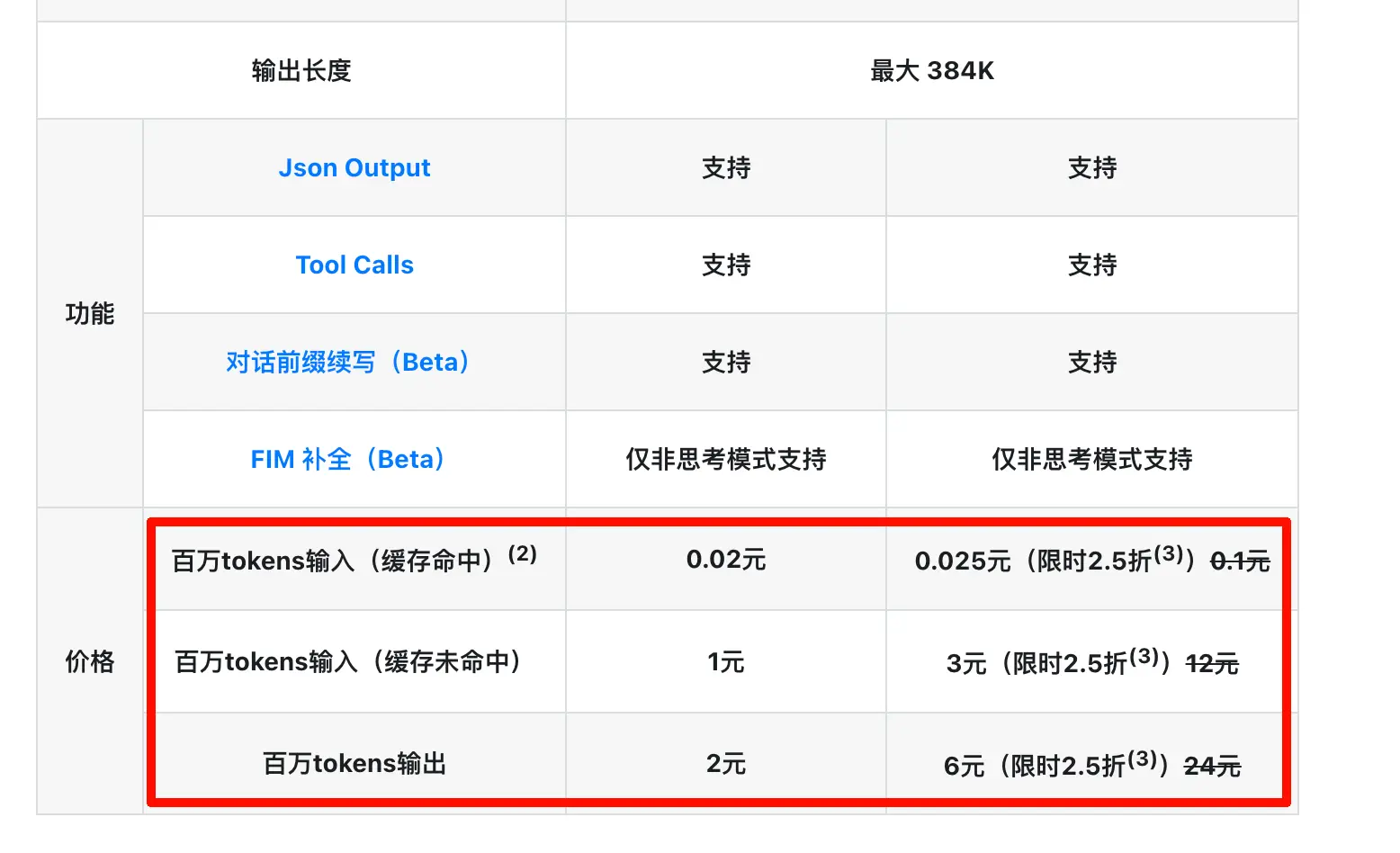
没想到过了两天Pro模型直接限时2.5折了(而且这个折扣我怀疑是长期的),昨天还把缓存命中的价格降到了原来的十分之一!那还说啥,站起来用力蹬就完事了!
这才是我们熟悉的DeepSeek!前几天我还抨击了某些Coding Plan难抢和体验不好,DeepSeek这是要直接把API总体价格降到比Coding Plan还低的架势啊。尤其是现在多家Coding Plan禁止你除了编程以外的使用,就更显得DeepSeek有诚意了。
某些Coding Plan的API如果你接入了翻译,可能就把你封了,但是DeepSeek无所谓,你爱咋用咋用。
GPT5.5和DeepSeek V4表现出色,我已经在考虑下个月停止续费Claude了。并且身边的大佬已经试过了。

不过话说回来,肯定会有人好奇这个输入输出、缓存到底是什么意思?
我们先介绍一下什么叫做缓存命中。
打个比方:你去常去的那家面馆,第一次点"牛肉拉面加蛋不要香菜",老板要现切牛肉、揉面、煮蛋、备料,整套流程走下来挺慢。十分钟后你朋友来了,也点了一模一样的,老板发现料还在锅里热着、面也是同一锅,直接给你端上来——这就是"命中"。
AI 处理你的输入,本质上要把你发过去的所有文字(包括系统提示词、历史对话、你这次的问题)全部"嚼一遍",转成模型内部的中间状态。这一步是真烧算力的。
如果 AI 发现你这次发过去的内容,开头一大段和上一次完全一样,它就直接把上次嚼好的中间状态拿来用,不用重新嚼一遍——这就是缓存命中。
注意三个关键点:
- 必须是前缀完全一致。哪怕你在开头多加了一个空格、改了一个标点,缓存就废了,等于从头再来。
- 有时效。不同厂商不一样,比如 Anthropic 默认只有 5 分钟(你上个厕所就过期了),想要 1 小时档得加钱(按基础输入价的 2 倍计费)。DeepSeek 这边大概几小时到几天。
- 同一对话天然容易命中。因为对话每多一轮,新的输入 = 之前的全部历史 + AI 的回复 + 你的新问题,前面那一大段历史是完全相同的,自然就命中了。
缓存是否命中将会极大地影响价格,这也是为什么我建议在同一个对话中只聊相关内容,不仅仅是为了上下文的记忆,还因为会影响缓存命中。开新对话等于从零开始算钱,接着聊等于打折。
因此百万 tokens 输入(缓存命中)、百万 tokens 输入(缓存未命中)、百万 tokens 输出的意思就是:
百万 tokens 输入(缓存未命中):你这次发过去的内容里,AI 没法复用之前算好的部分、必须从头嚼一遍的那部分文字,按这个价格算。第一次开聊、新会话、改了开头的提示词,都属于这种情况。
百万 tokens 输入(缓存命中):你这次发过去的内容里,开头那一段恰好和之前某次完全一样、被 AI 识别出来直接复用的部分,按这个(便宜很多的)价格算。同一对话里聊到第二轮、第三轮,前面的历史就属于这一类。
百万 tokens 输出:AI 生成给你的那段回答,按这个价格算。这个永远是最贵的,因为"生成"比"理解"更耗算力——一个是 AI 在脑子里反复打草稿、挑词、组句,一个是 AI 看一遍材料。
举个具体例子感受一下。假设你在用 DeepSeek 改一段 3000 tokens 的代码:
- 第一次提问:输入 3000 tokens(全部未命中)+ AI 输出 500 tokens
- 接着追问"这段还能优化吗":输入变成 3500 多 tokens(其中 3500 是之前的历史,全部缓存命中;只有你新加的几十个字算未命中)+ AI 输出 600 tokens
- 再开新对话重新粘代码问同样的问题:又是 3000 tokens 全部未命中
如果未命中价格是命中价格的 10 倍,那么"在同一对话里追问"和"开新对话重新问",光是输入这一项的费用差距就能拉到接近 10 倍。
所以这次 DeepSeek 把缓存命中价格直接打到原来的十分之一,配合 Pro 模型 2.5 折,对那些长上下文 + 多轮对话的使用场景(比如 Coding、文档分析、长聊天)几乎是骨折级的让利。如果你写过 Skill 或者搭过自动化流程,知道一个长 prompt 反复调用是常态,这次降价对应的真实节省比账面上看起来还要夸张。
最后给一个实操建议:养成在同一对话里聊完一个主题再开新对话的习惯,别动不动就"清空开新的"。不光是 AI 记得住你,也是真的能省钱。
总结
今天学到了什么:
- 缓存命中是什么 —— AI 把上次嚼过的输入存了一份,这次开头一样就直接复用,省下重新计算的算力,价格也跟着打折
- 三个关键条件 —— 必须是前缀完全一致、有时效(不同厂商从几分钟到几天不等)、同一对话天然容易命中
- 三种价格分别指什么 —— 缓存未命中 = 重新算的输入;缓存命中 = 复用的输入(最便宜);输出 = AI 生成的回答(最贵)
- 为什么输出最贵 —— “生成"比"理解"更耗算力,AI 在脑子里反复打草稿,价格通常是输入未命中的几倍
核心要点:
- 同一对话接着聊,等于在自动打折;动不动开新对话,等于每次都按原价付钱
- 改提示词要改在末尾,开头一动缓存就废了
- 长上下文 + 多轮对话的场景(Coding、文档分析、长聊天)受益最大,DeepSeek 这波降价对这类用户基本是骨折
顺便我再吐槽一下CC,这是蒸馏了GPT5.4吧!

随手附个广告 📚
我有两本电子书:《Obsidian 实战手册》《AI 实战手册》 各 ¥29.9,两本 ¥49.9。搜索微信号加我,备注「OB 实战」/「AI 实战」/「两本」:
