Skill se tornou um método indispensável no meu fluxo de trabalho diário. Para qualquer coisa que se repita três vezes ou mais, penso em transformá-la em uma skill — não apenas para economizar tempo, mas para garantir que a direção e as etapas não saiam dos trilhos toda vez. Pelo menos em teoria.
Mas a IA Ainda Sai dos Trilhos
Essa afirmação é um pouco exagerada. A realidade é que a IA ainda pula etapas. Pegue a skill de escrita para conta pública do WeChat que uso todos os dias. Configurei para me mostrar o primeiro rascunho para revisão, e só depois que confirmo que está ok ela prossegue para a revisão de erros de digitação. Parece simples, certo? Mas quando ela realmente executa, fica pulando etapas: termina o primeiro rascunho sem me mostrar e vai direto para a revisão e edição. Quando percebo, ela já revisou o arquivo silenciosamente. Quando a chamo a atenção, ela se desculpa, diz “desculpe, foi minha culpa”, e depois faz de novo na próxima vez. Desculpas não resolvem o problema.
Por que a IA Sempre Pula Etapas
Esse problema é um pouco contraintuitivo. No começo, pensei que a IA não era inteligente o suficiente, mas já estava usando ChatGPT 5.4 e Opus 4.6, que são modelos grandes de ponta. Depois, pensei que as regras não eram claras o suficiente, então revisei as regras na skill várias vezes. Ajudou um pouco, mas não resolveu a causa raiz. Após algumas pesquisas, aprendi que a IA pular etapas não é sobre “não ver as regras” — é determinado pelo mecanismo de geração:
- “Impulso de aceleração” impulsionado por probabilidade. Modelos de linguagem grandes essencialmente preveem o próximo token. O peso de completar a tarefa é naturalmente maior do que “ficar na etapa 7 esperando o usuário”. A sensação de conclusão é seu impulso intrínseco.
- Regras decaem em contextos longos. As regras que você define no início têm seu peso de atenção diluído quando o modelo atinge o token 3000. Especialmente se você enterrar as regras em um documento de skill longo, elas são marginalizadas mais facilmente.
- Particularmente grave no modo automático. Quando uso o modo automático para escrever artigos, o modelo tende a “executar todas as etapas de uma só vez”. Minha janela para intervir fica ainda mais estreita.
- CLAUDE.md e documentos de skill são essencialmente “restrições suaves”. São prompts que dependem da “autodisciplina” do modelo para serem seguidos. E a autodisciplina é frágil quando confrontada com “quero terminar esta tarefa rapidamente”.
Então a conclusão é: Restrições verbais falham sob pressão orientada a tarefas. Simplesmente escrever documentos, adicionar pontos de exclamação ou fazer PUA na IA só pode aliviar o problema, não curá-lo. Para realmente corrigir, você precisa tirá-lo da zona de autodisciplina do modelo — tornar fisicamente impossível pular etapas. É aí que entram os Hooks.
O Que é um Hook
Claude Code tem um mecanismo chamado Hook. Não é uma skill, não é um prompt, e não é o mesmo que CLAUDE.md — é um script shell local anexado a pontos-chave no ciclo de vida do Claude Code. A diferença chave:
- CLAUDE.md / skill são observados e executados pelo modelo — o modelo pode ignorá-los.
- Hook é imposto pelo sistema — o modelo não pode ignorá-lo mesmo que queira.
Uma frase chave da documentação oficial da Anthropic sobre Hooks: Hooks são acionados por eventos do sistema, não por decisões do modelo. Isso significa que os hooks estão anexados a todo o runtime do Claude Code. Cada chamada de ferramenta que o modelo faz — Write, Edit, Bash — deve primeiro passar pelo hook para revisão. Se o hook retornar deny, é negado, mesmo se você tiver --dangerously-skip-permissions ativado. Isso é o que chamo de “restrição rígida” — não deixar a IA fazer suas próprias escolhas, mas forçar suas chamadas de ferramenta a passar por uma auditoria real de script shell.
Pontos de acionamento comuns de Hook:
PreToolUse: Intercepta antes da IA chamar uma ferramenta.UserPromptSubmit: Processa sua mensagem antes de entregá-la à IA.SessionStart: Acionado quando uma sessão inicia ou é retomada.Stop: Acionado quando Claude termina uma resposta.
Foco nos dois primeiros — eles são suficientes para construir “travamento de etapas”.
Na Prática: Portão de Etapas para Minha Skill de Conta do WeChat
Toda conversa é inútil sem um exemplo concreto. Esta captura de tela é a interface do Claude Code enquanto escrevo este artigo. Na caixa vermelha, a IA me pede para responder “pass step3 0090” — esta senha é exatamente o Hook do Portão de Etapas em ação. O texto que você está lendo agora foi escrito depois que enviei a senha e o hook a permitiu.
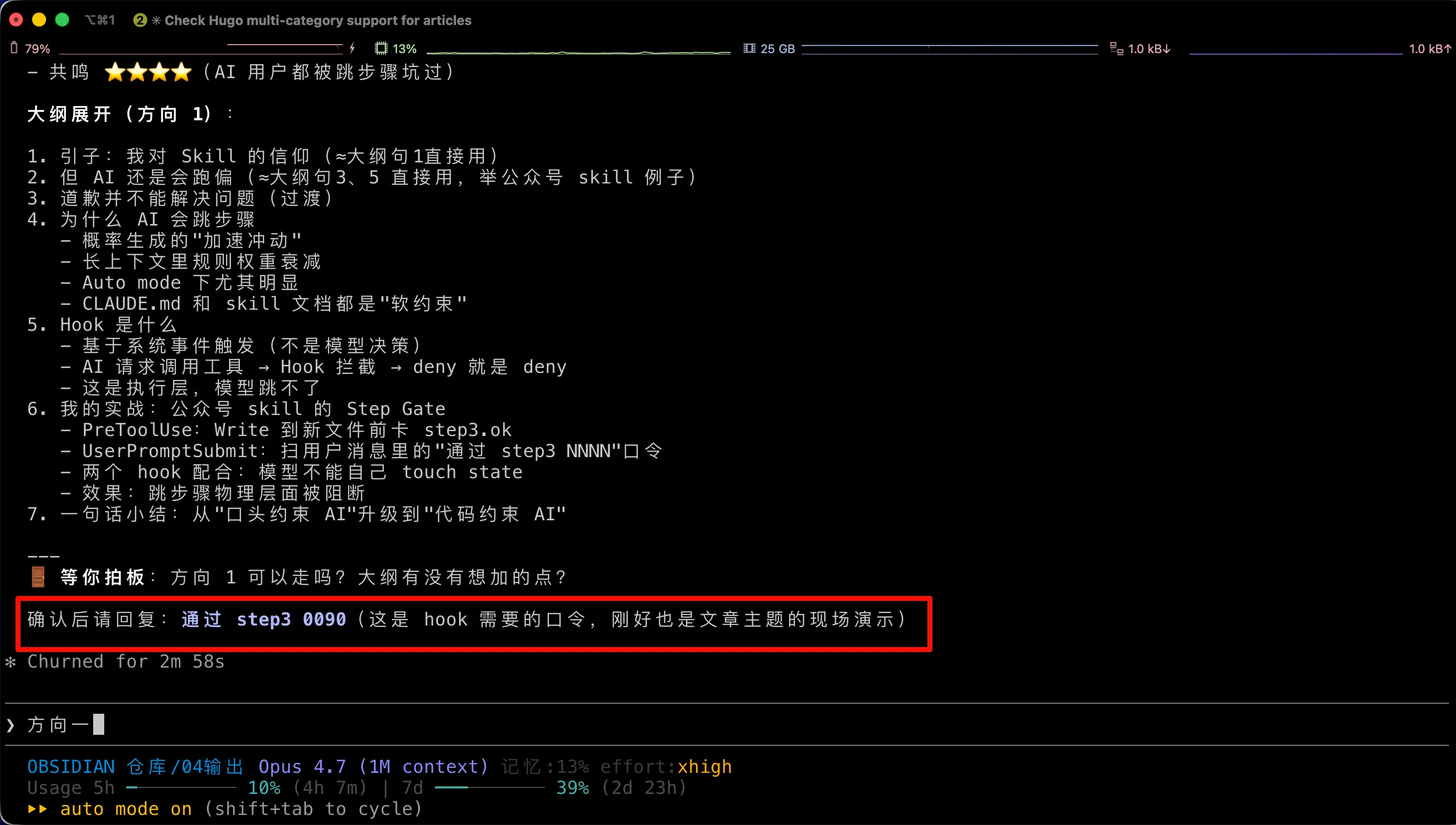
O Portão de Etapas inteiro usa apenas dois scripts shell mais uma pequena configuração no settings.json. Vou detalhar.
Registrar Dois Hooks no settings.json
Adicione isso ao ~/.claude/settings.json:
"PreToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{ "type": "command",
"command": "~/.claude/skills/writing-gongzhonghao/scripts/gate_check.sh" }
]
}
],
"UserPromptSubmit": [
{
"hooks": [
{ "type": "command",
"command": "~/.claude/skills/writing-gongzhonghao/scripts/gate_mark.sh" }
]
}
]
Esta configuração significa:
- Toda vez que a IA quer escrever ou editar um arquivo,
gate_check.shé executado primeiro para revisão. - Toda vez que envio uma mensagem,
gate_mark.shé executado primeiro para analisá-la.
gate_check.sh Lida com a Interceptação
A lógica deste script é bem simples:
- Se a IA quer escrever um novo arquivo
04-Output/NNNN xxx.md(correspondente à Etapa 3: criar um novo artigo), ela verifica se o arquivo de estadostep3.okexiste. Se não, retornadeny. - Se a IA quer editar um artigo existente (correspondente à revisão após a Etapa 7), ela verifica se
step7.okexiste. Se não, também retornadeny.
Ao negar, também inclui um prompt: “Discussão do tópico da Etapa 3 não confirmada: Por favor, me dê a aprovação do esboço/direção primeiro. Após confirmação, responda ‘pass step3 NNNN’ para criar um novo arquivo.” Este prompt é exibido diretamente para a IA, então ela sabe que está travada e me pede a senha.
gate_mark.sh Lida com a Liberação da Senha
Como eu “libero”? Não posso deixar a IA se liberar — isso não seria nenhuma restrição. A regra é: Apenas quando minha mensagem contém uma senha específica o arquivo de estado é tocado. gate_mark.sh é executado toda vez que envio uma mensagem, escaneando por padrões como pass stepN NNNN. Se corresponder, ele toca um arquivo .ok no diretório correspondente.
Então a cadeia completa se torna:
- IA termina o esboço e quer criar um novo artigo → bloqueado por
gate_check.sh - IA me pede a senha: “Por favor, confirme a direção, responda ‘pass step3 0090’”
- Eu envio “pass step3 0090” →
gate_mark.shtoca step3.ok - IA tenta criar o arquivo novamente →
gate_check.shpermite desta vez - Após terminar o primeiro rascunho, quer prosseguir para a revisão de edição → bloqueado novamente por step7.ok
- Após eu ler o rascunho e enviar “pass step7 0090” → a revisão pode começar
Durante todo o processo, a IA não tem espaço para “autodisciplina”. Ela não pode pular etapas mesmo que queira, porque suas chamadas de ferramenta são bloqueadas no nível do sistema.
Tapar uma Brecha: IA Não Pode Tocar Arquivos de Estado Sozinha
Após projetar a primeira versão, fiquei olhando para o plano por um tempo e encontrei uma brecha — e se a IA usar Bash para touch step3.ok por conta própria? Isso não contornaria a restrição? Então adicionei uma regra específica no documento de skill: A IA não deve tocar arquivos de estado sozinha, caso contrário estaria removendo suas próprias restrições. Esta regra em si ainda é uma restrição suave, mas combinada com a interceptação rígida dos hooks, forma um loop suficientemente fechado — desde que a IA não viole ativamente esta regra (e Claude é realmente cooperativo), a restrição do hook é real. Se quiser ser mais rigoroso, você pode adicionar um correspondente de Bash no PreToolUse para também bloquear comandos como touch. Mas ainda não cheguei a esse ponto; está bom o suficiente.
Se Você Não Entende de Código, Não Entre em Pânico
Você não precisa escrever esses scripts shell ou configurações JSON você mesmo (na verdade, eu também não sei escrevê-los). A abordagem é simples: jogue este artigo e seu arquivo de skill para o Claude ou Codex, deixe ele ler e ajudar a modificar — criar scripts onde necessário, modificar settings.json onde necessário. A IA é particularmente confiável para esse tipo de tarefa de “configurar ambiente de acordo com a documentação”, muito mais estável do que escrever código do zero. Ela aprende os princípios do artigo enquanto escreve hooks de acordo com seus requisitos de skill, e o resultado raramente sai dos trilhos.
Resumo em Uma Frase
CLAUDE.md, documentos de skill, marcadores em negrito, repetir três vezes, PUA — tudo isso são restrições verbais sobre a IA. Funcionam, mas têm um teto baixo.
Hooks são restrições de código sobre a IA. Eles movem as regras para um lugar que a IA não pode alcançar, transformando “seguir regras” de uma questão de autodisciplina do modelo em um requisito obrigatório do ambiente de execução.
Se você se pega repetidamente dizendo à IA “Por que você está pulando etapas de novo?”, é hora de considerar usar Hooks para restringi-la.