A DeepSeek finalmente lançou o modelo V4. Estive testando nos últimos dias e a experiência está ótima, especialmente o modelo Flash com uma excelente relação custo-benefício. Meu mini-programa de controle de gastos pessoais, que antes tinha um tempo de resposta de 5 segundos, agora caiu para 2,5 segundos. Em uma palavra: suave!
O único ponto negativo é que o modelo Pro não é tão barato. Segundo o site oficial, os preços vão cair ainda mais quando a oferta de chips nacionais aumentar no segundo semestre do ano.
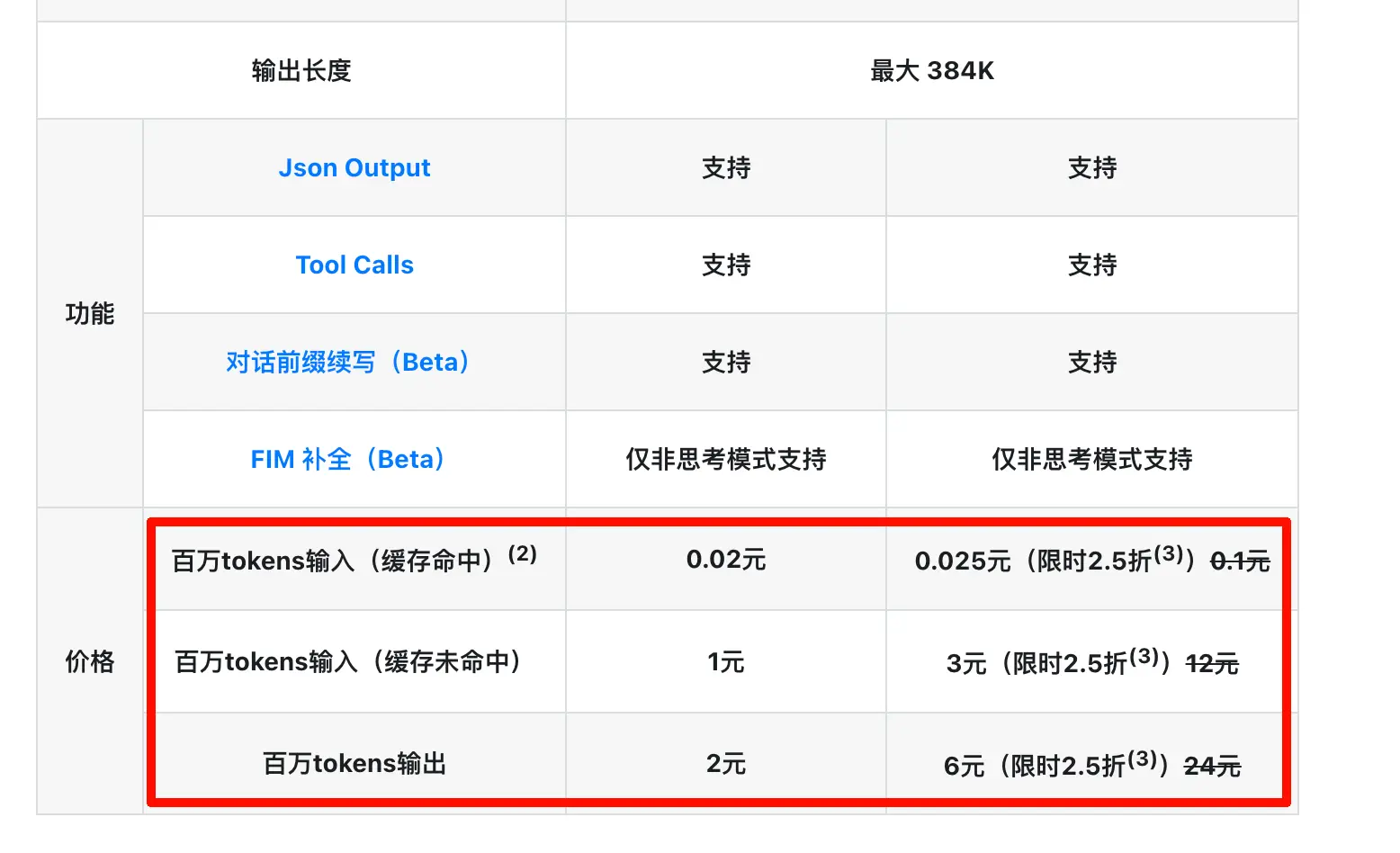
Inesperadamente, dois dias depois o modelo Pro ganhou um desconto temporário de 75% (e suspeito que esse desconto pode se tornar permanente). Ontem, eles também reduziram o preço do cache hit para um décimo do original! O que mais posso dizer? Hora de se levantar e pedalar com força!
Esta é a DeepSeek que conhecemos! Há alguns dias eu estava criticando certos Coding Plans por serem difíceis de obter e terem uma experiência ruim. A DeepSeek parece estar diretamente reduzindo o preço geral da API para abaixo do desses Coding Plans. Especialmente agora que muitos Coding Plans proíbem o uso fora da programação, a sinceridade da DeepSeek se destaca ainda mais.
As APIs de alguns Coding Plans podem te banir se você integrar tradução, mas a DeepSeek não se importa — use como quiser.
O GPT-5.5 e o DeepSeek V4 estão com um desempenho excelente. Já estou considerando cancelar minha assinatura do Claude no próximo mês. E alguns especialistas ao meu redor já testaram.

Mas voltando ao ponto principal: alguns de vocês devem estar se perguntando: o que realmente significam entrada, saída e cache?
Vamos primeiro introduzir o que significa um acerto de cache.
Aqui vai uma analogia: Você vai à sua loja de macarrão habitual e pede “macarrão puxado com carne e ovo, sem coentro” pela primeira vez. O dono precisa fatiar a carne fresca, sovar a massa, cozinhar o ovo e preparar os ingredientes — todo o processo leva um tempo. Dez minutos depois, seu amigo chega e pede exatamente a mesma coisa. O dono vê que os ingredientes ainda estão quentes na panela e que o macarrão é do mesmo lote, então serve diretamente — isso é um “acerto”.
Quando a IA processa sua entrada, ela essencialmente precisa “mastigar” todo o texto que você envia (incluindo prompts do sistema, histórico da conversa e sua pergunta atual) e convertê-lo em um estado intermediário interno para o modelo. Essa etapa consome muitos recursos computacionais.
Se a IA descobrir que o conteúdo que você enviou desta vez tem um grande segmento inicial exatamente igual ao anterior, ela reutiliza diretamente o estado intermediário da última vez, sem precisar mastigar tudo de novo — isso é um acerto de cache.
Observe três pontos importantes:
- Deve ser uma correspondência exata de prefixo. Mesmo se você adicionar um espaço extra ou alterar uma pontuação no início, o cache é invalidado e começa do zero.
- Tem um limite de tempo. Varia conforme o provedor. Por exemplo, o padrão da Anthropic é de apenas 5 minutos (expira enquanto você está no banheiro). Se quiser a opção de 1 hora, precisa pagar extra (2x o preço base de entrada). O cache da DeepSeek dura de algumas horas a alguns dias.
- A mesma conversa naturalmente tende a acertar. Porque a cada nova interação em uma conversa, a nova entrada = todo o histórico anterior + resposta da IA + sua nova pergunta. O grande histórico anterior é exatamente igual, então acerta naturalmente.
Se o cache acerta ou não afeta muito o preço. É por isso que recomendo discutir apenas conteúdo relacionado dentro da mesma conversa — não apenas por causa do contexto, mas também por causa do cache. Iniciar uma nova conversa significa pagar do zero, enquanto continuar a conversa significa obter um desconto.
Portanto, os significados de “por milhão de tokens de entrada (acerto de cache)”, “por milhão de tokens de entrada (falha de cache)” e “por milhão de tokens de saída” são:
Por milhão de tokens de entrada (falha de cache): A parte do conteúdo que você envia desta vez que a IA não pode reutilizar de cálculos anteriores e precisa mastigar do zero é precificada a esta taxa. Isso inclui primeiras conversas, novas sessões ou prompts alterados no início.
Por milhão de tokens de entrada (acerto de cache): A parte do conteúdo que você envia desta vez em que o segmento inicial coincide exatamente com uma instância anterior e é diretamente reutilizado pela IA é precificada a esta taxa (muito mais barata). Na mesma conversa, o histórico da segunda, terceira rodadas, etc., se enquadra nessa categoria.
Por milhão de tokens de saída: A resposta gerada pela IA é precificada a esta taxa. Esta é sempre a mais cara, porque “gerar” consome mais poder computacional do que “compreender” — um envolve a IA rascunhando, escolhendo palavras e formando frases repetidamente em sua mente, enquanto o outro envolve apenas a IA revisando o material.
Vamos usar um exemplo concreto para visualizar. Suponha que você está usando a DeepSeek para modificar um código de 3000 tokens:
- Primeira pergunta: Entrada de 3000 tokens (todos falha) + saída da IA de 500 tokens
- Depois pergunta “Isso pode ser otimizado ainda mais?”: A entrada se torna mais de 3500 tokens (dos quais 3500 são histórico anterior, todos acerto de cache; apenas as poucas dezenas de novas palavras que você adicionou contam como falha) + saída da IA de 600 tokens
- Iniciar uma nova conversa, colar o código novamente e fazer a mesma pergunta: Outros 3000 tokens todos falha
Se o preço de falha é 10 vezes o preço de acerto, então a diferença de custo apenas na entrada entre “fazer uma pergunta de acompanhamento na mesma conversa” e “iniciar uma nova conversa para perguntar novamente” pode ser de quase 10 vezes.
Então, desta vez a DeepSeek reduziu drasticamente o preço do acerto de cache para um décimo do original, combinado com o desconto de 75% no modelo Pro. Para casos de uso com contextos longos + conversas de múltiplas rodadas (como programação, análise de documentos, bate-papos longos), isso é quase um corte de preço para os ossos. Se você escreveu Skills ou configurou fluxos de automação, sabe que chamar repetidamente um prompt longo é a norma. A economia real dessa redução de preço é ainda mais dramática do que parece no papel.
Finalmente, uma dica prática: Crie o hábito de terminar um tópico dentro da mesma conversa antes de iniciar uma nova. Não fique sempre “limpando e começando do zero”. Além de a IA se lembrar de você, também vai economizar dinheiro.
Resumo
O que aprendemos hoje:
- O que é um acerto de cache — A IA armazena a entrada que mastigou da última vez. Se o início for o mesmo desta vez, ela reutiliza diretamente, economizando poder computacional, e o preço é descontado proporcionalmente.
- Três condições principais — Deve ser uma correspondência exata de prefixo, tem um limite de tempo (varia de minutos a dias entre provedores), e a mesma conversa naturalmente tende a acertar.
- O que significam os três preços — Falha de cache = entrada que é recalculada; Acerto de cache = entrada reutilizada (mais barato); Saída = resposta gerada pela IA (mais caro).
- Por que a saída é a mais cara — “Gerar” consome mais poder computacional do que “compreender”; a IA rascunha repetidamente em sua mente, e o preço geralmente é várias vezes o da falha de entrada.
Principais conclusões:
- Continuar na mesma conversa significa descontos automáticos; iniciar novas conversas com frequência significa pagar o preço total toda vez.
- Modifique os prompts no final; se você alterar o início, o cache é invalidado.
- Cenários de contexto longo + conversa de múltiplas rodadas (programação, análise de documentos, bate-papos longos) são os mais beneficiados. Os cortes de preço da DeepSeek são essencialmente para quebrar os ossos nesses casos de uso.