省流版:解决方案
如果你只想要答案,不想看分析,这里是解决办法:切换回 Opus 4.5。
方法一:临时切换 每次启动的时候用这个命令
claude --model claude-opus-4-5
方法二:设置别名(推荐)
这也是我自己用的办法
在 ~/.zshrc 或 ~/.bashrc 里加一行:
claude4.5() { claude --model claude-opus-4-5 "$@"; }
保存后 source ~/.zshrc,以后直接输 claude4.5 启动。
方法三:改默认模型
claude config set model claude-opus-4-5
代价:4.5 的上下文窗口是 200K,4.6 是 1M。如果你经常处理超长文档,4.6 还是有优势。但对大多数日常任务,200K 够用了。
以下是详细分析,想知道"为什么会这样"可以继续往下看。
Opus4.6真的变蠢了
最近用 Claude Code 是不是感觉它变蠢了?
我前几天写代码,让 Claude 帮我改一个 bug,它来回改了 5 次都没改对。每次都信誓旦旦说"已修复",结果一跑还是报错。以前这种 bug 一次就搞定了。
后来我试着切换到 Opus 4.5——就是现在默认 4.6 的上一代——同样的 bug,一次就修好了。
这让我开始怀疑:是不是新版本反而不如旧版本?
我不是唯一有这种感觉的人,网上和身边都是这种感觉。
证据一:STUPIDMETER 排行榜
有个叫 STUPIDMETER 的开源项目专门做 AI 模型的实时监测(https://aistupidlevel.info/)。它不是一次性跑个分就完事,而是持续跑 140 多个编码和调试测试,从正确性、稳定性、恢复能力、效率等多个维度打分。
代码在 GitHub 上完全公开,任何人都能审查。
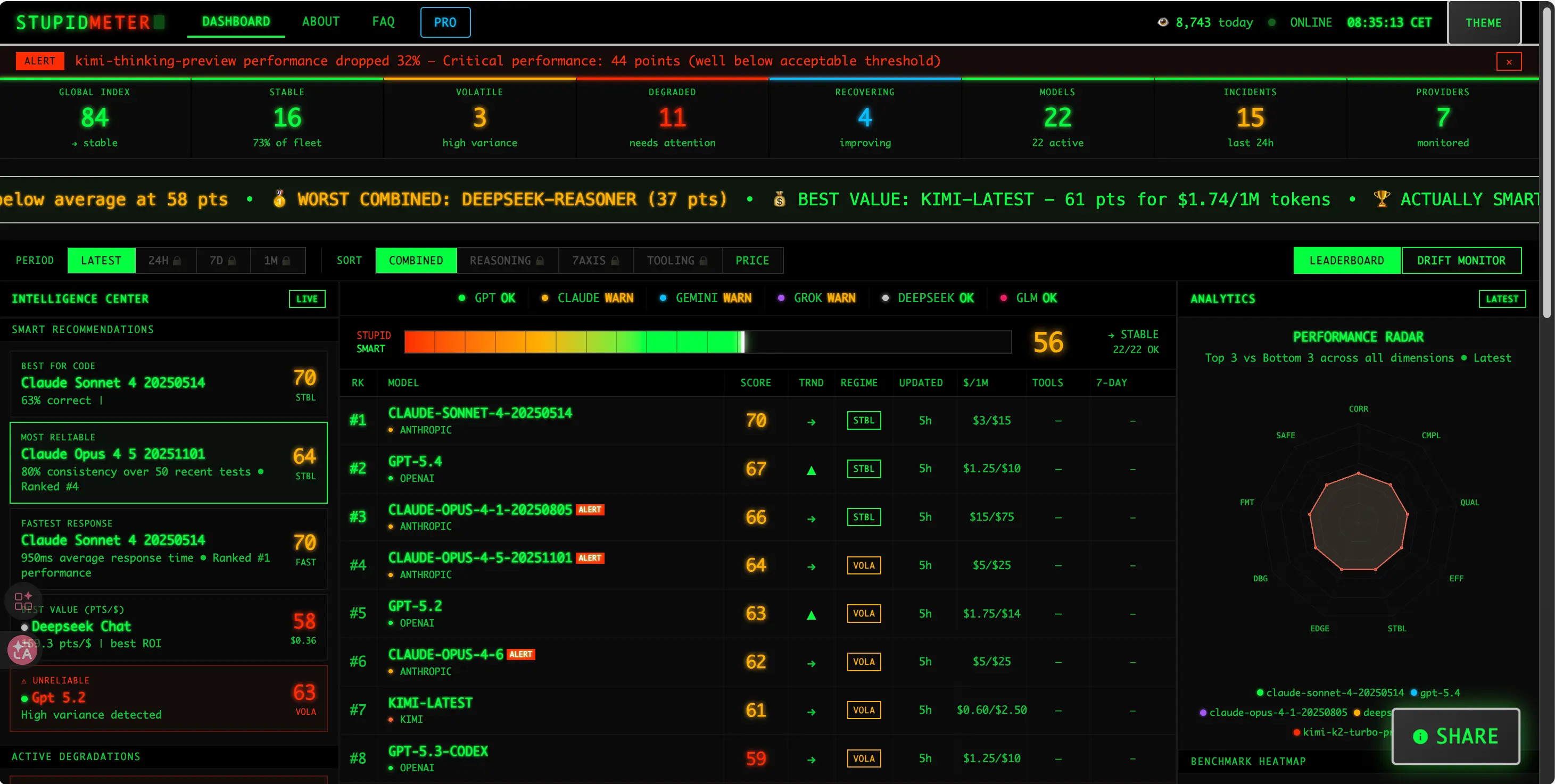
看看最近的排行榜:
| 排名 | 模型 | 分数 |
|---|---|---|
| #1 | Claude Sonnet 4 (2025.05.14) | 70 |
| #2 | GPT-5.4 | 67 |
| #3 | Claude Opus 4.1 (2025.08.05) | 66 |
| #4 | Claude Opus 4.5 (2025.11.01) | 64 |
| #6 | Claude Opus 4.6 | 62 |
注意看 Opus 这一列:版本越新,分数越低。
4.1 是 66 分,4.5 是 64 分,最新的 4.6 只有 62 分,还被标了个 WARN。
更离谱的是,Sonnet 4(一个比 Opus 便宜的"小模型")拿了 70 分,比所有 Opus 版本都高。
当然,这个榜单也有局限性——它主要测编码任务,不覆盖通用对话。而且作为一个相对较新的项目(2025 年 9 月才被报道),还没有经过学术界的严格验证。
但趋势是有参考价值的:Opus 越新分数越低,这不是随机波动,是连续三个版本的持续下滑。
证据二:AMD 高管的 6852 条对话
这不只是一个小网站的测试结果。
AMD 的一位 AI 总监公开了他和 Claude 的 6852 条对话记录,做了详细分析。这个人不是普通用户,是硅谷大厂的技术高管,每天重度使用 AI 写代码。
他的结论是:Opus 4.6 的思维深度比 4.5 下降了 67%。
什么是"思维深度"?简单说就是 AI 在回答问题之前"想"了多久。Claude 有一个 thinking 模式,会在回答之前先做推理。以前会想 3 分钟的问题,现在 1 分钟就草草交卷了。
他还算了一笔账:因为 4.6 变得更容易敷衍,需要反复重试才能得到满意的结果,他的 API 费用从之前的 $345/月暴涨到 $42,121/月。
122 倍。
这件事后来被 The Register、InfoQ 等科技媒体报道。Anthropic 最终承认了存在"基础设施问题",但强调"不是故意降级"。
证据三:社区的声音
Reddit 和 GitHub 上,关于"Claude 变蠢了"的帖子获得了超过 1060 个赞同。
这不是小众吐槽,是用户的集体反馈。
评论区的描述高度一致:
- “以前一次能搞定的任务,现在要反复提醒”
- “长对话后明显开始糊弄”
- “代码质量肉眼可见地下降”
- “给它明确的指令也会自作主张简化”
当这么多独立的用户报告相同的问题,这就不是个案了。
我的实测:到底哪里出了问题?
看到这些证据后,我想自己验证一下。
我设计了几组测试,同时让 4.5(我当前用的版本)和 4.6(通过子代理调用)回答同样的问题。
测试一:经典智力题
- 狼羊白菜过河
- 蜗牛爬井
[1,2,3].map(parseInt)返回什么
结果:两个版本都答对了。
测试二:复杂任务
我给了一个多步任务,要求:
- 分析一段代码的所有问题(至少找出 5 个)
- 解释每个问题为什么是问题
- 给出修复后的完整代码
- 写 3 个测试用例
- 分析时间复杂度和空间复杂度
结果:4.6 找出了 7 个问题,每一步都执行了,还给了详细的复杂度分析。
测试三:需求细节保持
给了 10 条详细需求写一个函数,要求写完后逐条检查是否满足。
结果:4.6 全部满足,还主动做了检查清单。
测试四:记忆力测试
在对话开头给一段信息(猫的名字、年龄、喜欢吃什么、几点起床),然后问 5 个无关的技术问题,最后再问开头的信息。
结果:4.6 全部记住了。
测试五:模糊任务
只说"帮我看看这段代码,有什么问题吗?“不明确告诉它要做什么。
结果:4.6 找出了 4 个问题,给了完整修复方案。
实测结论
在短对话、明确任务的场景下,4.6 表现依然不错。
那问题出在哪?
根据社区反馈和我的体感,“降智"可能更多发生在:
- 长对话后:上下文积累到一定程度后开始敷衍
- 开放性任务:没有明确指令时更容易选择省力的方案
- 需要主动发现问题的场景:被动回答还行,主动思考变弱了
这就引出了下一个问题:为什么会这样?
原因分析:三个猜测,哪个靠谱?
猜测一:算力分配不均
我有一个问题一直想不通:如果 Anthropic 算力不足,为什么不是所有模型都变慢/变蠢?为什么 Sonnet 反而分数最高?
一个可能的解释是:不同模型配置了不同的算力配额。
这不是我瞎猜。AI 模型的推理是有成本的——每多"想"一秒,就多烧一分钱。公司完全有动机对不同产品线设置不同的"思考预算”。
Sonnet 是 Anthropic 的主力产品。大多数用户用的是 Sonnet(便宜、速度快),Claude.ai 网页版默认也是 Sonnet。这是他们的门面,绝对不能出问题。
而 Opus 呢?用户相对少,大多是付费的重度用户。这群人"忠诚度高”,不容易流失。而且 Opus 本身就贵,边际成本更高。
如果要省成本,先从 Opus 开刀是合理的商业决策。
这个猜测能验证吗?
很难直接验证。Anthropic 不会公开他们的资源分配策略。
但有一些间接证据:
- STUPIDMETER 的数据显示 Sonnet 4 分数比所有 Opus 都高
- 社区反馈中,抱怨 Opus 降智的比抱怨 Sonnet 的多
- Anthropic 在 2 月引入"自适应思维模式"后,Opus 的 thinking 时间明显变短了
猜测二:模型在持续修改
我有个朋友在外企做 AI,他们公司买了 Claude 的授权,在自己服务器上本地部署。
他说他们的版本很稳定,没有感觉到"降智"。
这很有意思。如果本地部署版稳定,说明问题不在模型本身,而在 Anthropic 线上版本的持续改动。
具体来说,Anthropic 在今年做了几件事:
2 月:引入"自适应思维模式"
这个功能会根据问题的复杂度,自动调整 AI"思考"的深度。简单问题少想一会儿,复杂问题多想一会儿。
听起来很合理——省资源嘛。
但问题是:谁来判断一个问题是"简单"还是"复杂"?
是模型自己判断。而模型有时候会误判。它可能觉得一个问题很简单,就浅浅想一下就回答了,结果答错了。
3 月:默认推理等级从"高"调到"中"
这是社区调查发现的。Anthropic 没有公开宣布,但有人对比了前后的 thinking 日志,发现默认的推理深度确实变浅了。
也就是说,AI 现在默认会选择更省力的方案,而不是最优方案。
这个猜测能验证吗?
可以间接验证:
- 对比本地部署版和云端版的表现(需要有企业授权)
- 对比同一天不同时段的回答质量(如果是服务端配置问题,可能会有波动)
- 观察 thinking 日志的长度变化
我没有本地部署版的权限,但从我朋友的反馈看,这个猜测是可能成立的。
猜测三:技术层面的 Bug
Anthropic 自己也承认了几个技术问题:
TPU 配置错误
部分请求被路由到了配置不对的服务器。这不是模型的问题,是基础设施的问题。相当于你本来应该坐高铁,结果被塞上了绿皮火车。
XLA 编译器 Bug
XLA 是 Google 开发的机器学习编译器。Anthropic 用它来优化模型推理。但有个 bug 会导致某些情况下排除掉最高概率的 token——也就是说,AI 该说的话没说出来。
想象一下:你问 AI 一个问题,它心里知道正确答案,但嘴上说出来的是第二正确的答案。这就是这个 bug 的效果。
上下文压缩过度
这是最致命的一个。
当对话超过 40% 的上下文窗口,系统会自动压缩之前的内容。压缩本身不是问题,问题是压缩得太狠了。
结果就是:长对话后 AI 会开始重复自己、前后矛盾、忘记之前说过的话。
这就解释了为什么社区反馈中"长对话后变蠢"是最常见的抱怨。
这个猜测能验证吗?
可以。
你可以做一个简单的测试:
- 开一个新对话,问一个复杂问题,观察回答质量
- 在同一个对话里继续问很多问题,把上下文堆到 40% 以上
- 再问一个类似复杂度的问题,对比回答质量
如果第二次明显变差,就说明上下文压缩在起作用。
当然,以上都只是我的猜测,没有官方证实。
不只是 Anthropic:国内厂商也在限流
算力问题不是 Anthropic 一家的困境。国内厂商也在面对同样的问题,只是表现形式不一样。
智谱 GLM:抢购 + 双涨价
我之前想买智谱的 GLM Coding Plan。
抢了好几次,每次都是掐着 10 点开抢,每次都是秒没。
后来我才知道,智谱从 1 月 23 日开始限量发售,每日可销售量降为之前的 20%。
你能想象那种感觉吗?你明明愿意付钱,也知道这个工具好,还愿意花时间折腾——但你就是买不到。
智谱今年已经涨了两轮:
- 2 月 12 日:国内涨 30% 起,海外涨 30%-60%,API 调用涨 67%-100%
- 4 月 8 日:发布 GLM-5.1,再涨 10%
之前有人说"国内抢不到可以买海外版"——现在这条路也堵上了。海外涨幅比国内更狠。
更扎心的是,根据网上反馈,就算抢到了体验也不好。不少用户吐槽 GLM Coding Plan 的实际表现和宣传有差距,有时候还不如直接调 API 稳定。
Coding 类模型是高并发、高显存消耗的怪物。厂商的算盘很清楚:限量 + 涨价,两头堵。宁可少卖一点,也不能亏本卖。
阿里通义灵码:砍掉低价版
阿里的操作更直接——直接把便宜的版本下架了。
4 月 13 日起,Coding Plan Lite 停止续费和升级。
原来 Lite 版 40 元/月,续费还能打五折只要 20 元。现在呢?只能买 Pro 版,200 元/月。
涨幅:10 倍。
这不是涨价,这是换赛道。把低端用户直接清出去,只服务付得起钱的用户。
这和 Anthropic 的问题是一回事吗?
本质上是一回事:AI 算力是有限的,但需求在爆发。
只是表现形式不同:
- 智谱选择限量供应——你想买,买不到
- Anthropic 选择悄悄降级——你能用,但不如以前好用
哪种更诚实?我觉得智谱的做法至少是明牌。Anthropic 的问题在于:用户不知道发生了什么。
你以为你在用顶配版,其实你可能在用降级版。你以为是你的问题,其实是他们的问题。
为什么 Sonnet 分数最高?
这是我最困惑的一点。
按理说 Opus 是旗舰版,应该比 Sonnet 强才对。但 STUPIDMETER 的数据显示,2025 年 5 月的旧版 Sonnet 4 拿了 70 分,比所有 Opus 版本都高。
我有几个猜测:
1. Sonnet 是主力产品,不敢动
大多数用户用的是 Sonnet。Claude.ai 网页版默认就是 Sonnet。这是 Anthropic 的门面,是拉新用户的第一印象。
如果 Sonnet 变蠢了,用户会立刻流失到 GPT 或者其他竞品。但 Opus 用户呢?都是付费的重度用户,粘性高,不容易走。
2. Opus 被当成实验田
付费高级用户反而成了小白鼠。新功能、成本优化,都先在 Opus 上试。试出问题了,再调整。
3. 那个旧版 Sonnet 没被改过
2025 年 5 月的 Sonnet 4 可能是"纯净版",没有加入后来的"自适应思维"和各种优化。它就是老老实实按照原来的方式跑,反而保持了最好的性能。
有时候"不更新"是最好的更新。
我们能做什么?
作为用户,能做的不多,但不是完全没有。
用脚投票是最直接的反馈。
如果你觉得 4.6 不好用,就切换到 4.5。Anthropic 会看到用户的选择。当越来越多人手动切换旧版本,他们自然会知道问题在哪。
但更根本的问题是:AI 公司需要更透明的变更日志。
现在这些"优化"都是静默进行的。用户只能通过体感去猜"是不是变蠢了",然后上网搜索、看社区讨论、做对比测试……
这本不该是用户的责任。
如果 Anthropic 能公开说"我们在 3 月把默认推理等级从高调到了中",用户至少知道发生了什么,可以自己决定要不要改回去。
信任建立在透明之上。
我理解 AI 公司有成本压力,有技术限制。但至少告诉用户发生了什么。不要让我们自己当侦探。
写这篇文章的时候,我一直在想一个问题:
当你发现你信任的工具在悄悄变差,你会怎么做?
换一个工具?忍着继续用?还是像我一样,花几个小时研究到底发生了什么?
也许这就是 AI 时代的新常态。工具在变,平台在变,游戏规则也在变。唯一不变的是:你得保持警觉,不能闷头用。
用 AI 的人分两种:一种是被 AI 用的人,一种是用 AI 的人。
区别就在于:你知不知道它在干什么。
随手附个广告 📚
我有两本电子书:《Obsidian 实战手册》《AI 实战手册》 各 ¥29.9,两本 ¥49.9。搜索微信号加我,备注「OB 实战」/「AI 实战」/「两本」:
