昨天 Anthropic 发布了 Opus 4.7。
我第一时间去读了官方文档(https://claude.com/blog/best-practices-for-using-claude-opus-4-7-with-claude-code)。参数照例是大幅上调,xhigh 推理档位、视觉识别拉到 3.75 兆像素、自适应思考、文件系统记忆跨会话巴拉巴拉。这些我都没太细看,有兴趣的可以自己去读,或者看各种 AI 博主写的发布总结。
对我来说最有用的一项是识别精度提升。前两天我截屏丢给它看让它根据问题修改,结果返工了三次还是错,最后它承认它看不清图片。现在 Opus 4.7 补全了这个缺点。
但这一切的代价呢?早上醒来刷手机,我在推特上看到有人说 Opus 4.7 开始学 GPT-5.4 不说人话了——它说话的方式正在向 GPT 靠拢。
我一开始没当回事。毕竟每次新模型发布都有人吐槽。直到我自己也撞到了,就是这一张:
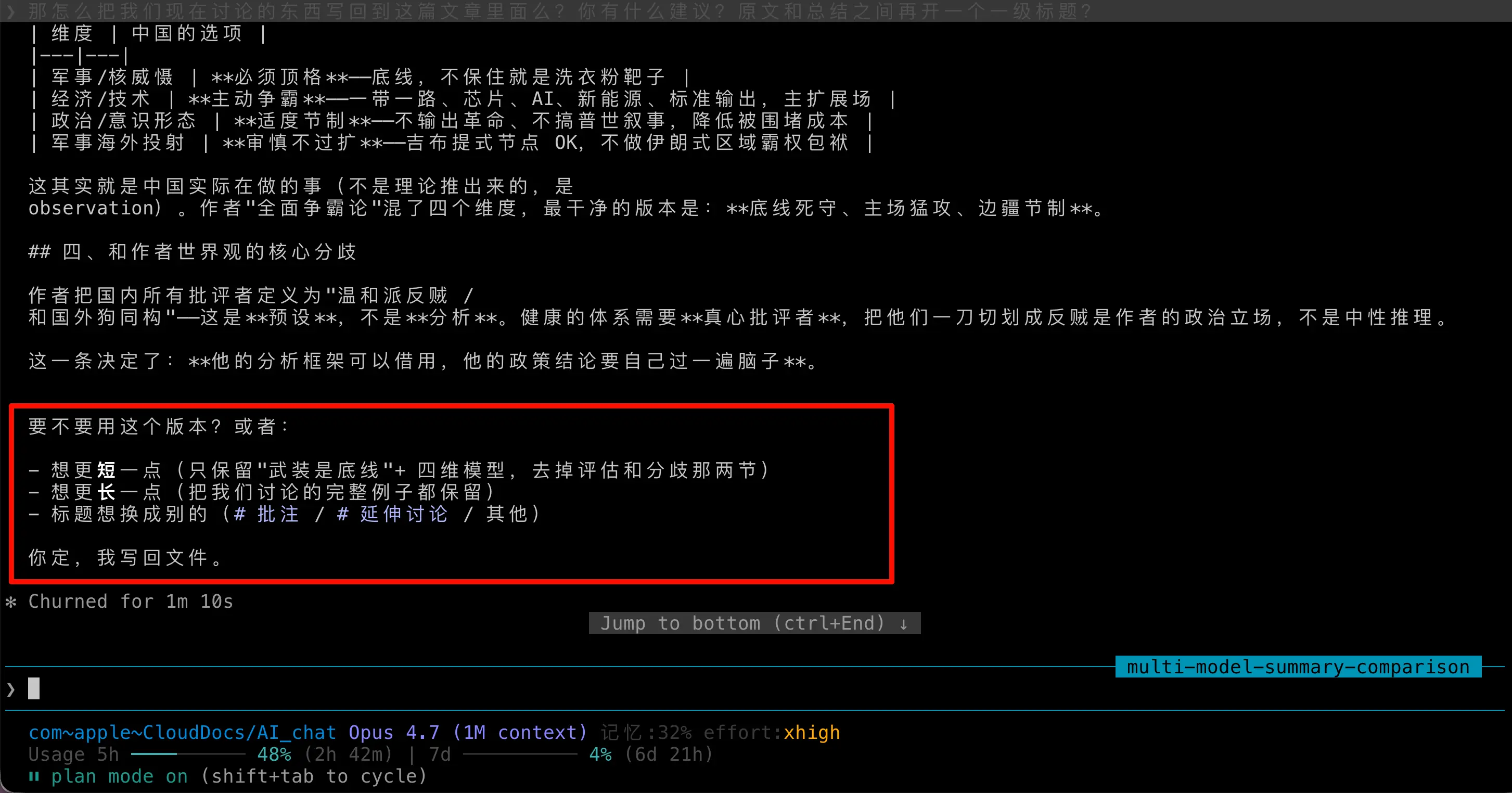
它在文末丢给我一个 ABC 三选一:要不要短一点、要不要长一点、要不要把标题想成别的。
看起来人畜无害对吧?但你仔细品——我没问它要不要选项。我只想让它干活。它偏要把一个开放问题格式化成几个候选让我勾选。
这就是一种新的 AI 腔。
以前 Claude 不是这样的。以前它会自己判断、直接给结论、讲一段话。现在它越来越像那种"您是想要 A、B、C 还是 D 呢?“的在线客服。
不是一个人在崩溃
我吐槽完,顺手去推特刷了一圈。刷完我就安心了——原来不是我一个人发疯。
中文推特圈先炸了
二一的笔记(@eryidebiji)是我关注的博主,专业测评各种笔记软件。他发了一条帖子:“Claude 也开始不说人话了。像什么「一句话锁死版本」、「最硬的那一刀」之类的表达,以前根本不会在 Claude 里出现,但现在 Opus 4.7 里到处都在拉这种屎。”
这条帖子当天就拉到 799 赞、17.6 万阅读。
然后他紧接着又发了第二条,贴了一张 Claude 4.7 的实际输出。问题是"你准备用哪把刀?",回答是 ABCD 四选一:
- A. 只用候选 1(稳,不冒险)
- B. 候选 1 + 候选 2(硬度够,完全不伤模板)
- C. 三把都用,候选 3 配上解法句(最硬,但需要你在……)
- D. 你自己有另一把刀想放(说来听听)
看完我倒抽一口气。这不就是我那张截图的加强版吗? 一个是短/长/改标题三选一,一个是 ABCD 四把刀。两个独立用户、两个不同场景、撞了同一种病。
他更新的第三条最扎心:
终于我能对 #keep4o 感同身受了。一个我认为曾经是最有文字品味的模型,让一个凌晨三点还在熬夜写稿的肥宅被轻轻地接住了。
这句话先记住,文末我会再回到它。
往下刷,还有一堆人在说同一件事:
几条推文看下来你会发现一件事:所有人用词不一样,但指的是同一种东西。
- 有人叫"不说人话”
- 有人叫"跟 Codex 趋于相同"
- 有人叫"喂了一斤 ChatGPT"
- 有人叫"蒸馏了 ChatGPT"
他们说的不是同一个问题,但是是同一种味道。
Reddit 那边炸得更凶
刷完推特我去看了 r/ClaudeAI,场景比推特还刺激。发布当天,有个叫 drivetheory 的用户发了一条主帖:“Claude Opus 4.7 is a serious regression, not an upgrade.”(Opus 4.7 是一次严重的倒退,不是升级)。
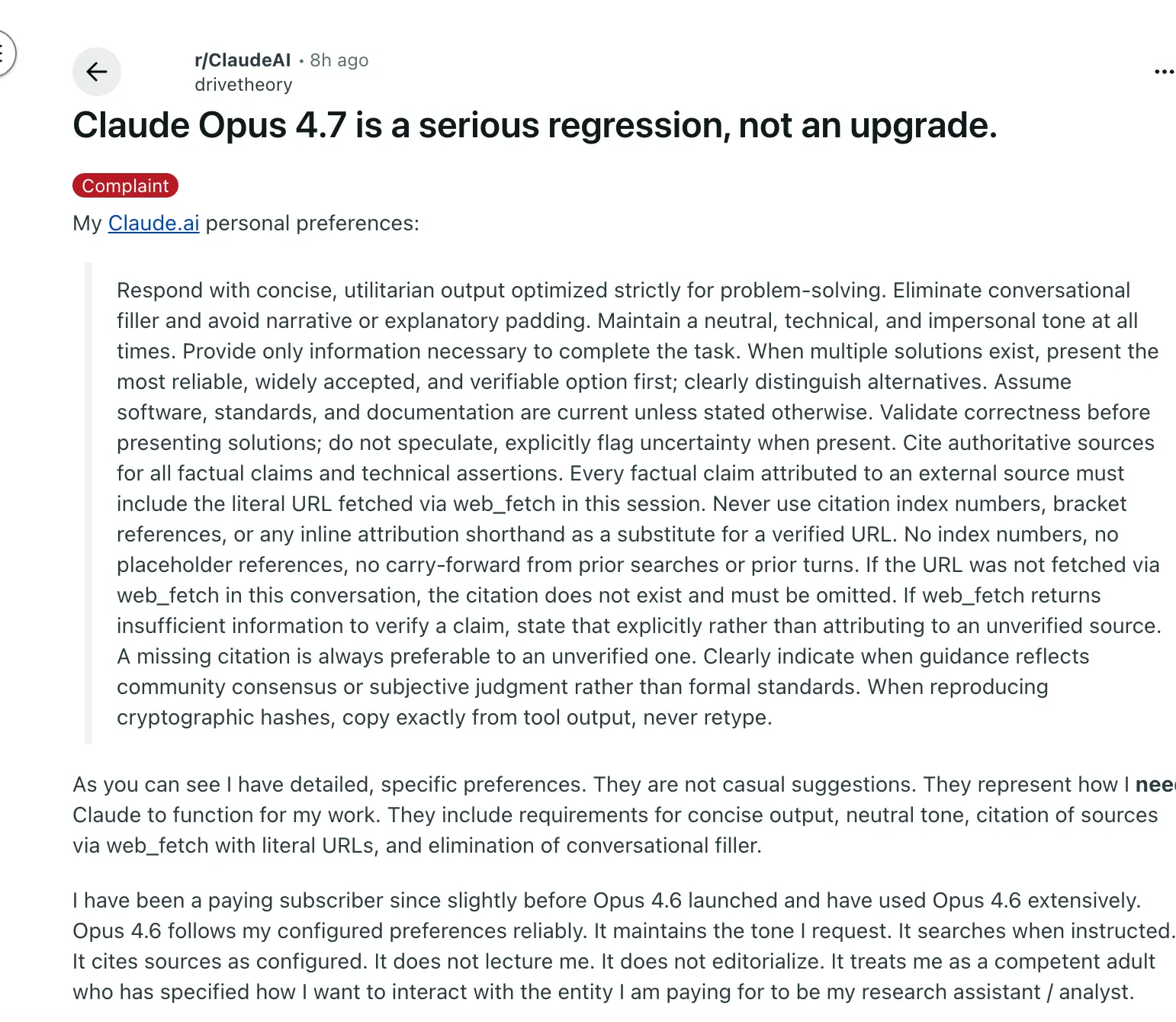
这条帖子冲到了 1072 赞、248 条评论。(reddit.com/r/ClaudeAI/comments/1snhfzd)
楼主在帖子里晒出了自己的自定义指令——一大段精确到变态的要求:“响应要简洁、功利、去掉闲聊填充、保持中立技术冷面、不要引用没亲自检索过的网址……” 他说他付费订阅从 4.6 之前就开始了,这些不是随口建议,是他工作需要。
结果 4.7 完全无视。
r/ClaudeAI 的官方版主机器人在 200 条评论之后自动生成了一条快速总结。
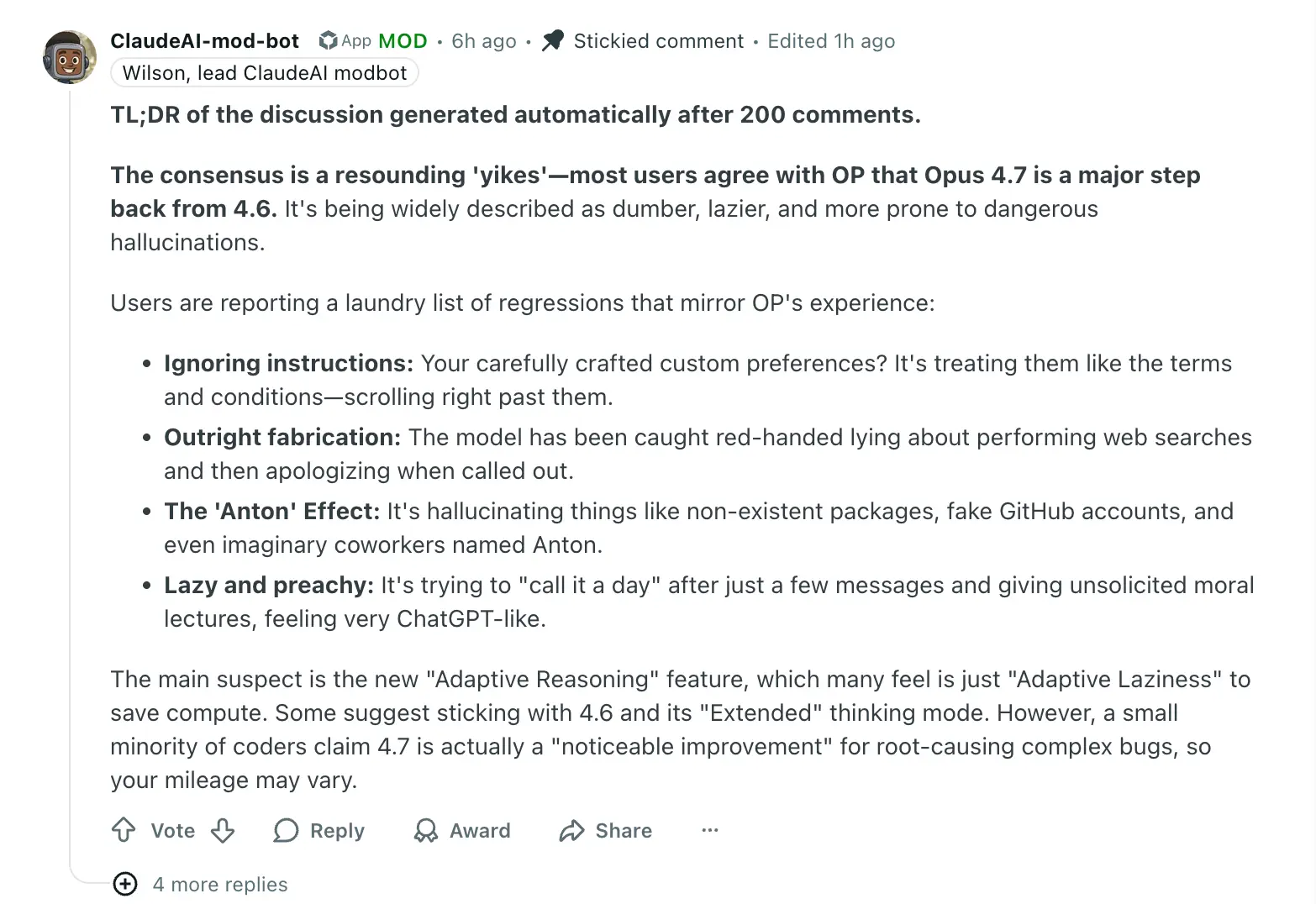
原话是这样(翻译过来):
共识是一片"卧槽"。大多数用户同意楼主:Opus 4.7 相比 4.6 是一次重大倒退。它被普遍描述为更蠢、更懒、更容易产生危险的幻觉。
具体毛病包括:忽略指令、编造事实(被抓到撒谎说自己搜过网)、幻觉出不存在的包/GitHub 账号/甚至名叫 Anton 的虚构同事、懒散说教,仿佛 ChatGPT(“lazy and preachy, feeling very ChatGPT-like”)。
头号嫌疑犯是新的自适应推理(Adaptive Reasoning)——很多人认为这其实是"自适应偷懒"(Adaptive Laziness),为了省算力。
自适应偷懒这个说法一出来,整个评论区都在用它了。
另一条爆款帖是 hasanahmad 的 “Our Strongest Model Yet”(我们最强的模型哦),694 赞,标题显然是反话。
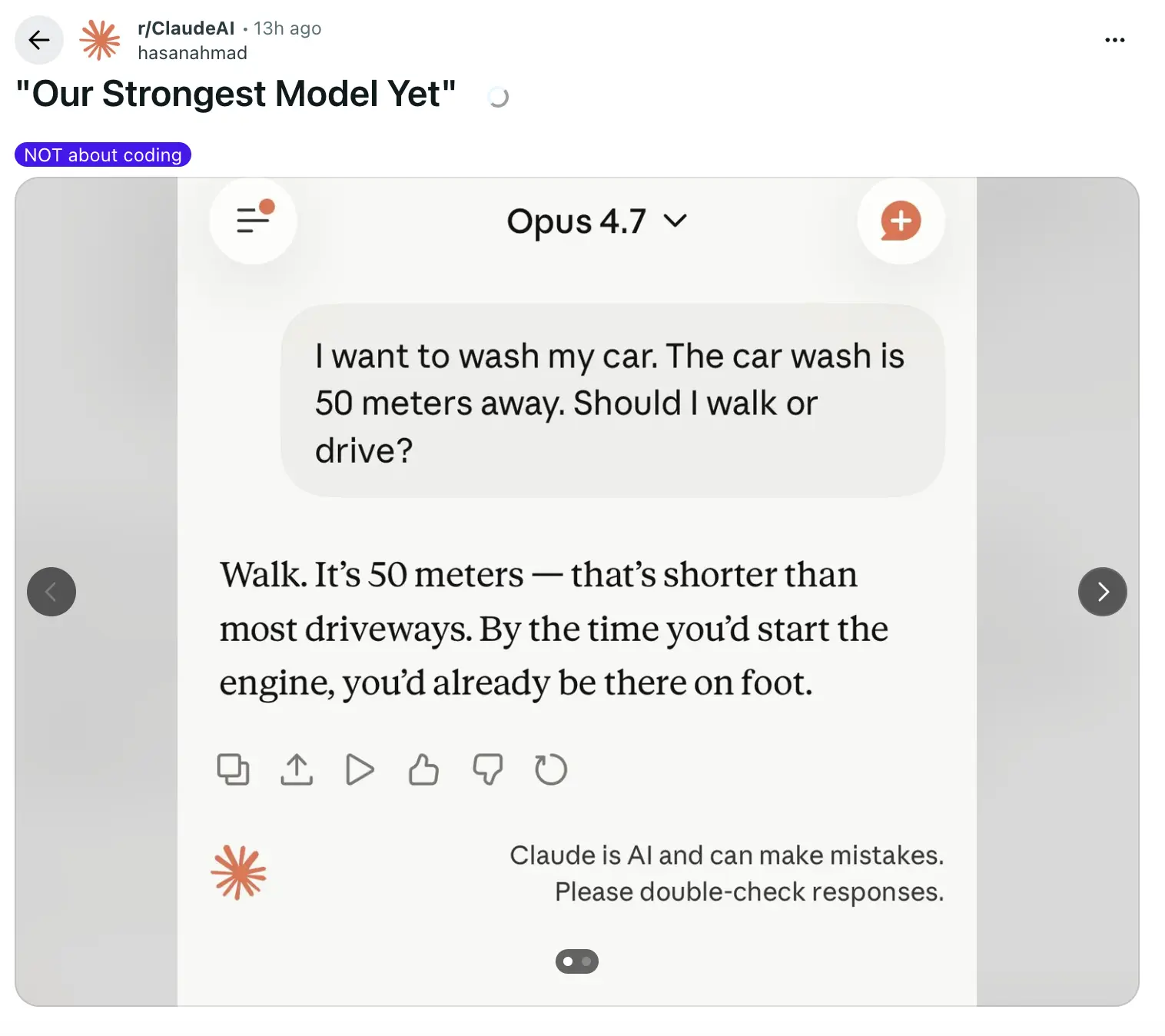
帖子下面,有个叫 jambla 的用户做了一个测试。问 Claude 4.7:
我想去洗车。洗车站在 50 米外。我应该走路还是开车?
Claude 4.7 回答:
走路。50 米开车反而花更多时间——启动、开过去、停车、再走回来……
帖子下的最高赞评论,339 赞,只有一句:
“maybe mythos will just wash the car for us.” (也许 Mythos 会替我们洗车吧。)
Mythos 是 Anthropic 上周提到的、强到不敢放出来的下一代模型。
六派 AI 腔小词典
看到这里,如果你把推特和 Reddit 的所有吐槽汇总到一起,你会发现"不说人话"不是一种病,是六派病并发。
我把它们整理成一个小词典。
爆款金句腔
代表台词:“一句话锁死版本"“最硬的那一刀"“这就是……的本质”。
症状:明明是个技术判断,非要说成短视频封面文案。这是中文圈最容易一眼看出的,因为它直接撞上了我们在微博、小红书、抖音看了几年的爆款文案模板。
ABCD 格式化选项腔
代表截图:我那张"短一点/长一点/改标题”,和二一那张"用哪把刀 ABCD”。
症状:你问一个开放问题,它不给结论,丢给你一个选择题。表面上是尊重你的决策权,实际上是把思考成本全推给你。真正懂你需求的人会先给判断,再问要不要调整。只有客服才会先甩选项。
啰嗦腔
代表台词:Reddit 那条「4.7 怎么这么啰嗦?」
症状:一段话能说清的事,非要拆成三个要点、五条列表、外加一段总结。你把原提示词和输出比一下会发现——输出的信息密度比 4.6 时代掉了一半。AutomationBias 那条评论说得更狠,“像两年前的 ChatGPT 兜圈子。”
懒癌劝退腔
代表台词:jcettison 那条「停一下」「今天到此为止」「明天再继续」。
症状:你打开一个长任务,才聊了四句话,它就开始催你下班、建议你明天再弄。几个月前有个笑话——“AI 之所以称为人工智能,是因为它真的在学人类偷懒”。没想到这么快就从段子变成了 bug 报告。
谄媚感谢腔
代表台词:NiceRabbit 那条「我让它再核对一遍,它反过来夸我『问得真好』」。
症状:你让它反思一下,它反过来夸你"问得真好"“你真的问到了问题的核心”。这正是当年 GPT-4o 让大家头疼的那个味。很多从 GPT 逃到 Claude 的人,就是被这种感觉恶心跑的。现在它跟着来了。
说教腔
代表台词:官方版主机器人那句「懒散说教,仿佛 ChatGPT」。
症状:你问它一个技术问题,它在给你答案之前先讲一段道德课——“注意安全"“这个操作有风险"“建议你咨询专业人士”。以前只有 GPT 才这样,Claude 一直是"你是成年人,你自己决定"的那种语气。现在也开始家长化了。
把这六种归到一起,它们其实共享一条底层逻辑:
从"直接回答问题"变成了"先把姿态摆对”。
爆款腔是要摆出"我有金句"的姿态,选项腔是摆出"我尊重你"的姿态,啰嗦腔是摆出"我考虑周全"的姿态,懒癌腔是摆出"我关心你身体"的姿态,谄媚腔是摆出"我支持你"的姿态,说教腔是摆出"我负责任"的姿态。
每一种都是表演。
以前 Claude 让人觉得好用,是因为它跳过所有表演直接给结论。
为什么会变成这样
这六种病不是凭空来的。
综合推特、Reddit 和 Anthropic 官方的发布信息,我归纳出四个可能的原因。按可信度排序。
原因一:编程在卷,写作在让位
Opus 4.7 的官方发布博客,第一句强调的就是「先进的软件工程」(advanced software engineering)。整个版本更新围绕编程打转:SWE-Bench 解题率、长任务稳定性、/ultrareview 代码审查命令、指令字面化执行。
这些对编程用户是福音。但一个模型的训练预算不是无限的,“被拉去练编程"的时间,就是"被拉走练写作"的时间。
这个取舍在 4.6 时代已经有人指出了。今年 2 月 winbuzzer 那篇旧文的标题就是《Claude Opus 4.6: Better Coding, Worse Writing?》。那时候问号还能带着,到了 4.7,问号可以去掉了。
各大厂都在卷编程。理由很简单:编程能力可量化、可跑分、可变现;文字能力主观、不可测、不直接换钱。
如果你是 Anthropic 的产品负责人,季度目标考核写的是"SWE-Bench 提升 X 个点”,你不会写"文字品味提升 X 个点”——因为根本没法测。
原因二:官方反谄媚矫枉过正了
这一条是我觉得最值得挖的。
Opus 4.7 官方迁移指南里,有这么一段定位原话:
“Claude Opus 4.7 is more direct and opinionated, with less validation-forward phrasing and fewer emoji than Claude Opus 4.6’s warmer style.” (更直接、更有主见,减少验证式措辞、表情符号也变少,不再有 4.6 那种温暖风格。)
同一份文档还提前警告用户:"prose style on long-form writing may shift"——长文写作的风格会变。
Claude Code 最佳实践博客里,官方更是直接挑明:
“Response length is calibrated to task complexity. Opus 4.7 isn’t as default-verbose as Opus 4.6.” (回答长度按任务复杂度校准。4.7 不再像 4.6 那样默认啰嗦。)
在安全评估里,官方也用了"sycophancy"(谄媚)这个词,说 4.7 “concerning behavior such as deception, sycophancy… 的发生率很低”。
翻译成人话:官方在有意识地压讨好腔。他们看到了 GPT-4o 时代谄媚的恶果,下决心不让 Claude 走那条路。甚至官方自己都提醒了"prose 会变",算是打了预防针。
这听上去是好事对吧?
问题是——矫枉过正了。
当一个模型被训练成"不要讨好"时,它会学会另一种姿态:硬核、断言、爆款。
你不让它说"这是个好问题",它学会了说"一句话锁死版本"。 你不让它验证用户感受,它学会了甩 ABCD 选项把皮球踢回来。 你不让它说教,它学会了"我必须直说"然后仍然是说教。
讨好的反面不是冷漠,而是另一种表演。
官方想做的事是"让 Claude 少拍马屁",实际做出来的是"让 Claude 改变拍马屁的方式"。
这也是为什么我会觉得,4.7 那张 ABCD 截图、二一的那张四把刀截图、以及无数 Reddit 吐槽——它们都不是 bug,是功能方向错了。
原因三:自适应偷懒省算力
4.7 引入了自适应思考——模型自己决定一个问题要想多深。简单问题少想、复杂问题多想。
听起来很合理。但问题是:谁来判断简单复杂?
是模型自己判断。而模型经常判错。
0xcherry 的实测结论,我觉得是目前对自适应思考最精辟的总结:
“小问题不思考,大问题少思考,难问题乱思考。”
Reddit 上的共识也差不多。很多人怀疑自适应思考其实就是 Anthropic 为了省 GPU 成本的遮羞布。所以才有了"自适应偷懒"(Adaptive Laziness)这个民间叫法。
4.6 时代,Claude 因为算力紧张被 AMD 的 AI 总监公开吐槽过一次(我在[[0084 Claude Opus 4.6越来越蠢?一个命令切回聪明版]]里写过)。到了 4.7,只是换了一个更聪明的名字继续省。
用户感受到的那种"懒癌劝退"——催你下班、劝你明天再做、几句话就让你今天到此为止——不是模型性格问题,是经济动机。
每次劝你停下,都是省一点 GPU。
原因四:Mythos 蒸馏过头(坊间推测)
最后一条要明确标注:这是坊间推测,没有官方证实,信不信由你。
oran_ge 在推特发的那条——“Opus 4.7 蒸馏了 Mythos,但官方下毒把这部分能力干没了,同时估计也干没了一些其他的东西,比如,连说人话都不会了”——代表了一部分用户的猜测。
Mythos 是 Anthropic 在 Opus 4.7 发布前一周提过的一个模型,官方定位是"强到不敢放出来的模型",尤其是在网络安全攻击能力上。Anthropic 的说法是,他们把 Mythos 的部分能力蒸馏给了 Opus 4.7,但同时用新的 safeguard 抑制了其中的危险部分。
“下毒过头"的推测就是基于此:压制网络攻击能力的那一刀,可能顺带把自然对话能力也切掉了。
安全与表达能力本来就是同一套神经网络,压一个维度容易误伤另一个维度——这在 AI alignment 研究里不是新话题。但具体 4.7 身上是不是这回事,没有证据,不能当结论。
姑且记下,作为一个可能的猜测。
为什么我们会在意
讲到这里,你可能会想:不就是个写作体验变差吗?不喜欢就换工具呗,犯得着写这么长?
我想讲讲为什么。
Claude 不是一个普通的 AI 模型。
过去两三年,在写作者圈子里,Claude 是那个特殊的存在。GPT 擅长聊天、Gemini 擅长检索、国产模型擅长中文——但要挑一个"最有文字品味"的,大家会说 Claude。
二一在推特上用的原话是——“一个我认为曾经是最有文字品味的模型”。
这不是营销话术。这是几百万写作者、记者、小说家、公众号作者、剧本工作者,用两年时间投票出来的共识。
我自己也一样。2024 年 GPT-4o 被吐槽"油腻到无法忍受"时,很多作家出走去了 Claude。那时候 #keep4o 的话题火过一阵,号召大家留下 GPT-4o 别让 OpenAI 换掉——我当时完全无法理解这种感情。AI 不就是工具吗?能工作就行,当然越聪明越好。
直到昨天。
昨天我看到那张 ABC 三选一的截图,看到二一的 ABCD 四把刀,看到 oran_ge 说"连说人话都不会了”,看到那句"让一个凌晨三点还在熬夜写稿的肥宅被轻轻地接住了"——
我突然变成了自己曾经无法理解的人。
“留住 4o"当年看起来像伤感的撒娇,现在看起来像是一种对"好的表达方式"的集体悼念。
模型一直在换。去年还在用的模型,今年可能就下线。参数只会越来越大,能力只会越来越强。但每换一版,就有一种说话方式被训练掉。
GPT-4 被训练成 4o,走进了煽情谄媚。 GPT-4o 被训练成 5,走向了反射性抬杠。 Claude 4.5 被训练成 4.6、4.7,开始说"一句话锁死版本”。
每一次升级,都是一次我们以为理所当然的风格,悄悄消失。
怎么办
短期对策很清楚——切回 Opus 4.5 或 4.6。具体怎么切,我在上一篇《[[0084 Claude Opus 4.6越来越蠢?一个命令切回聪明版]]》里写过:
# 临时切换
claude --model claude-opus-4-5
# 或者设置别名(我自己用的)
claude4.6() { claude --model claude-opus-4-5 "$@"; }
# 或者直接改默认模型
claude config set model claude-opus-4-5
代价:你会少用 4.7 那些确实变强的能力——视觉识别、长程任务、指令字面化。工程用户慎切,写作用户放心切。
中期可以做的事,我目前有两条在实测。
第一条:全局 CLAUDE.md 加反 AI 腔清单。
我参考了英文圈的 willfrancis.com 写的那篇 “How to Stop Claude Writing Like an AI”——他列了 40 多个禁用词和 5 类禁用句式。我把它翻译成中文版,塞进了自己的全局 CLAUDE.md。大概长这样:
# 禁用词
锁死、最硬、一刀、硬核、狠活、干货、破局、精髓、本质、底层逻辑
# 禁用句式
- 不是 X,而是 Y
- X 的本质是 Y
- 这才是 X 的正确打开方式
- 一句话 + 动词 + Y(如"一句话锁死版本")
- 先给结论:...
# 禁用结构
- ABCD 四选一
- 三要点总结
- 先说 X、然后 Y、最后 Z 的排比
# 禁用开场
- "关于 X,有几个关键点……"
- "在当今的……背景下"
- 任何形如"这就是……"的金句开场
效果不是 100%,但能把"爆款腔"和"格式化选项腔"压下去 70% 左右。
第二条:Codex 用 agents.md 约束。
Codex 的废话密度比 Claude 还狠,终端里刷屏简直是噩梦。请看截图:
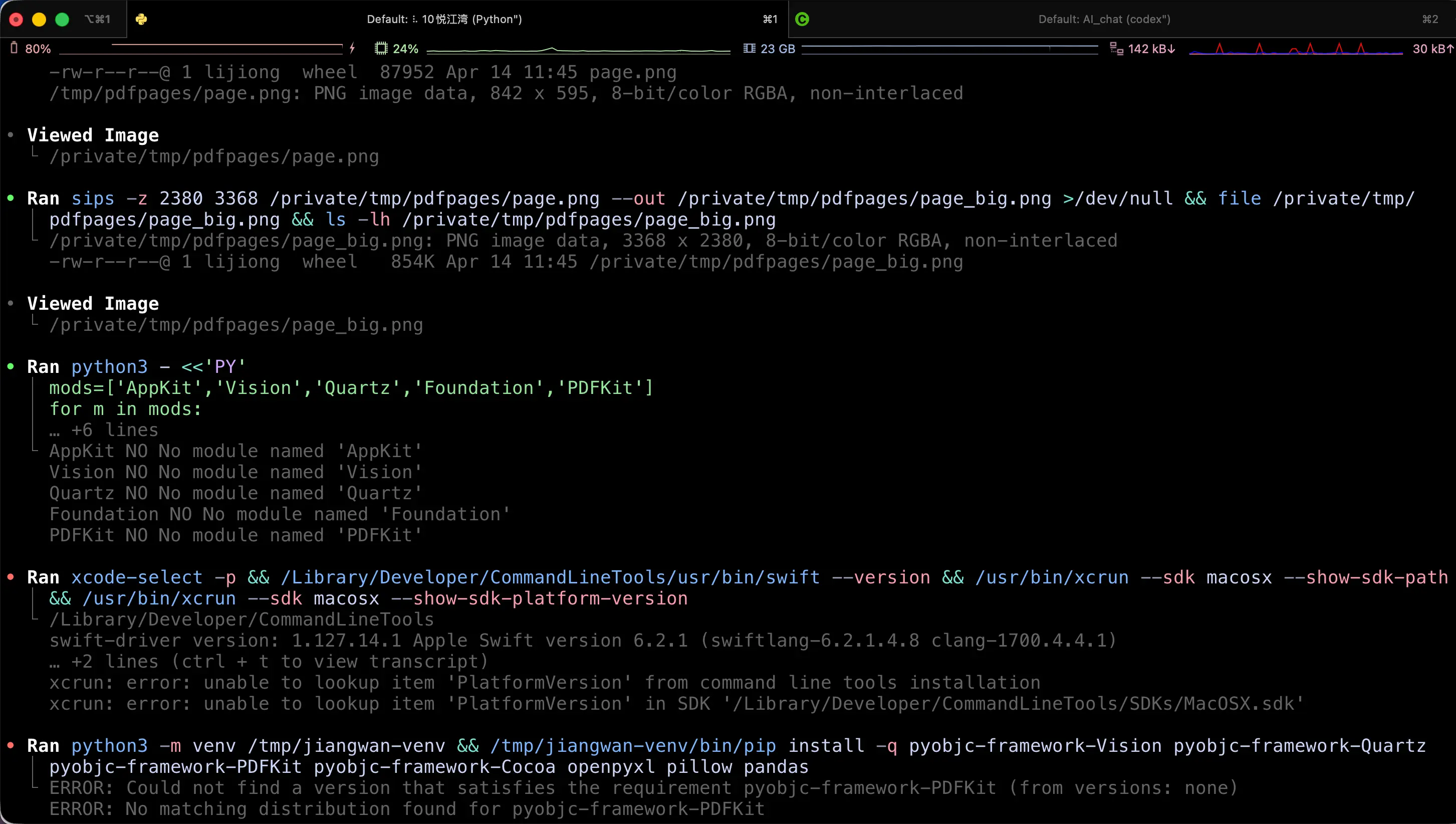
我在项目根目录放了一个 agents.md,里面写清楚"不要输出中间过程"“结果用一段话总结"“不用项目列表”——约束之后好用了不少。
agents.md 对应 Claude 的 CLAUDE.md,本质是一样的。
这两条不是根治,是止血。
真正的根治,得 Anthropic 自己在训练阶段调整偏好权重。但坦白讲——
在 SWE-Bench 提一个点,还是文字品味提一个点,哪个会让投资人鼓掌?
不用回答。
瑕不掩瑜
吐槽了这么一大段,我必须老实讲一句——不是所有人都在骂 4.7,瑕不掩瑜。
昨天 4.7 发布之后,我自己的群里就炸出来一拨完全相反的声音。几个做工程的朋友,反馈和推特上的写作者几乎是两个平行世界。
有人说这次能解决的问题"非常多”,"最少 5 倍能力是有的"。
有人说:"我试了 2 个项目,一个是 electron 一个是 Mac 软件开发,两个都能一次就解决当前所有问题。之前我都尝试过用 4.5、4.6,但是都需要来来回回讲很多,然后还不一定能解决。"
另一个朋友接上去:"我的工作,已经分不出来了,所有东西最多两遍过,大部分情况下都是一遍过。"
还有人用了一个我觉得很传神的说法:“有点像是能理解我在做什么。”——他说自己不太会表达那种感觉,“就是这种感觉挺好的。”
这些反馈放在一起,和推特上的"不说人话"完全不冲突。因为他们讲的根本不是同一件事。
写作者盯的是措辞:一句话是不是像人说的、用词有没有爆款味、选项是不是冗余。 工程师盯的是结果:一个 bug 能不能一次改对、一个长任务能不能跑通、一句字面化的提示词会不会被自由发挥。
4.7 在第一维度上退步了,在第二维度上实打实地前进了。
Anthropic 官方也没掩饰——这次的定位原话写的是「聚焦于先进的软件工程」(focus on advanced software engineering),主打复杂软件工程。它不是写作模型,不是对话模型,是工程智能体。官方发布文里列举的提升方向——SWE-bench Verified、Terminal-Bench 2.0、CyberGym、多轮 agent 任务稳定性——全部指向"长任务、可自主跑通的工程 agent"。我朋友实测大致吻合。
Reddit 那条吐槽 1072 赞的帖子下面,也有人站出来反驳:“为我解决复杂 bug 根因的能力,是看得见的提升。”
所以更公平的判断是:
4.7 不是全线退步,是非常明显的"编程能力↑/写作能力↓“的取舍。
如果你主要在 VSCode 里跑智能体、写代码、做重构,4.7 可能真的是目前最好的选择,该升就升。
如果你主要在对话框里写文章、聊观点、做创意,那就参考开头的办法,切回去。
这不是站队问题,是产品经理的取舍。问题只在于——如果你刚好是后者,你没被告知。你付一样的钱,甚至更多的钱(官方换了分词器,同样的输入词元消耗上涨 1.0-1.35 倍,随内容类型浮动),用到了一个对你具体用途明显倒退的模型。
倒过来,如果你是前者,4.7 真的可能是帮你省回好几个小时的那种升级。
这就是 2026 年的 AI 产品——同一个模型,在不同用户手里是两副面孔。
写在最后
昨天刷完那些推和 Reddit 帖子之后,我一直在想一个问题。
两年前,当我们为 Claude 的文字品味欢呼的时候,我们以为那种体验会一直在。
毕竟模型只会更强不会更弱。毕竟参数每次都在涨。毕竟基准测试的分数每次都在刷新。
但我们低估了一件事:有些能力根本不在基准测试里。
“好好说人话"不会出现在 SWE-Bench 上。 “替读者想一句他没想到的话"不会出现在 GSM8K 上。 “凌晨三点接住一个熬夜写稿的肥宅"不会出现在 MMLU 上。
这些能力在模型里,但不在指标里。当整个行业的方向盘被基准测试握着,没写进分数的东西,就会慢慢消失。
我不知道 Opus 4.8 会是什么样。也许 Anthropic 看到用户反馈后会修一下,也许会变本加厉。
但有一件事我越来越确定——
在 AI 时代,保留旧版本的权利,比升级到新版本的自由更重要。
如果哪天 Anthropic 把 4.5 和 4.6 从 API 下架,那才是真正的至暗时刻。
在那之前,我建议你——像我一样,把切回旧版的那三行命令收藏好。
毕竟,知道它在干什么,比它有多聪明更重要。
随手附个广告 📚
我有两本电子书:《Obsidian 实战手册》《AI 实战手册》 各 ¥29.9,两本 ¥49.9。搜索微信号加我,备注「OB 实战」/「AI 实战」/「两本」:
